Публикация была переведена автоматически. Исходный язык: Английский


Один из ответов заключается в том, чтобы делать правильные вещи с минимальными затратами на эксплуатацию.
Мы можем использовать автоматическое масштабирование
Автомасштабирование, также известное как automatic scaling, - это функция облачных вычислений, которая позволяет автоматически регулировать мощность ваших ресурсов в зависимости от фактической рабочей нагрузки. Эта возможность гарантирует, что у вас будет необходимое количество вычислительных ресурсов для удовлетворения различных потребностей без ручного вмешательства. Автоматическое масштабирование обычно используется в облачных средах, таких как Amazon Web Services (AWS) и Microsoft Azure, для поддержания высокой доступности, оптимизации затрат и повышения производительности системы.
- Вертикальное автоматическое масштабирование Pod — VPA (вверх и вниз)
- Автоматическое масштабирование по горизонтали — HPA (Выход и вход)
- Динамическое автоматическое масштабирование
- Автоматическое масштабирование с прогнозированием
- Автоматическое масштабирование, управляемое событиями
Автоматическое масштабирование, управляемое событиями, позволяет запускать действия по масштабированию на основе определенных событий или условий. Например, вы можете масштабировать свое приложение в ответ на увеличение трафика пользователей, поступление новых данных или запуск определенного задания.
KEDA расшифровывается как Kubernetes Event-Driven Autoscaling, это проект с открытым исходным кодом, который обеспечивает автоматическое масштабирование, управляемое событиями, для контейнерных рабочих нагрузок, запущенных в Kubernetes. Это позволяет масштабировать приложения Kubernetes в зависимости от внешних событий, таких как сообщения, поступающие в очередь, количество HTTP-запросов или пользовательские триггеры событий. KEDA помогает сделать ваши приложения более эффективными и экономичными, а также реагировать на изменения в рабочих нагрузках.
Почему KEDA использует управление событиями
Kubernetes позволяет выполнять автоматическое масштабирование различными способами: по горизонтали, вертикали или по узлам.
- Поддержка только стандартных объектов Kubernetes (развертывание, набор с отслеживанием состояния, набор реплик) и использование сервера метрик
- Нет способа проследить за их поведением, поэтому вам нужно разработать свой собственный набор ключевых показателей эффективности, чтобы убедиться, что они работают должным образом. Итак, если HPA или VPA по какой-то непонятной причине не работают должным образом, вы не будете получать точные предупреждения.
- Не существует адаптера метрик, совместимого с вашим источником данных, для создания правил автоматического масштабирования на основе пользовательских показателей. Если у вас нет адаптера метрик, вам нужно использовать показатели ресурсов (ЦП или памяти).

KEDA заполняет два пробела, с которыми вы столкнетесь при создании распределенного облачного приложения на
огромный масштаб.
1. КЕДА дает вам больше контроля. Больший контроль над вашими экземплярами по сравнению с их запуском
в общедоступном облаке. Вы можете использовать существующий кластер Kubernetes и запускать свои функции, например Azure
, непосредственно рядом с другими компонентами вашей общей архитектуры приложения. KEDA
позволяет вам задавать пользовательские границы для масштабирования.
2. С другой стороны, KEDA позволяет масштабировать развертывания в Kubernetes на основе внешних
событий или показателей. В Kubernetes вы можете использовать Horizontal Pod Autoscaler (HPA) для масштабирования
Развертываний на основе показателей, генерируемых внутри кластера. Особенно при запуске
Kubernetes в сочетании с внешними облачными сервисами, такими как Azure Service Bus,
артефакты вашего приложения должны масштабироваться в соответствии с этими внешними показателями.
KEDA предоставляет структурированную, оптимизированную стратегию, позволяющую удовлетворить эти потребности, не усложняя
общую архитектуру.
- Эффективное использование ресурсов
- Архитектура, управляемая событиями
- Оптимизация затрат за счет нулевого масштабирования
- Гибкая интеграция (более 50 масштабируемых программ)
- Повышенная производительность
- Традиционное HPA: всегда минимальное количество модулей → более высокая стоимость
- KEDA позволяет масштабировать незанятые приложения до нуля
- Сокращает вычислительные ресурсы
- Пример: пакетное масштабирование процессора с 0 до 10 позволяет сэкономить до 70%
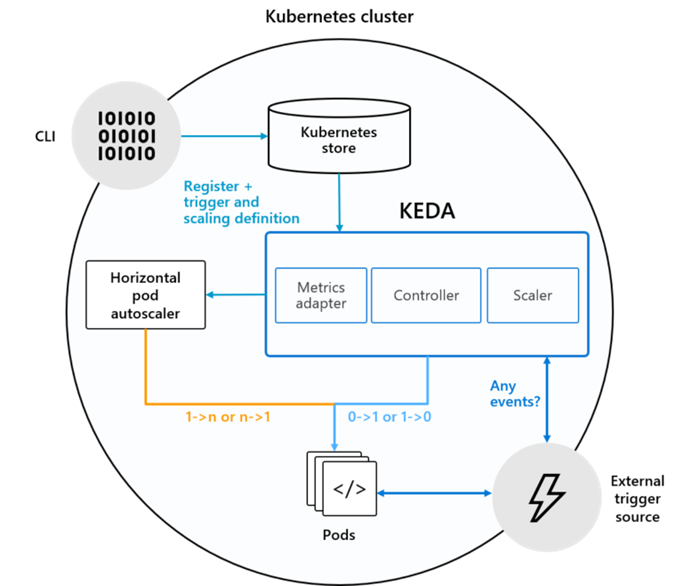
KEDA отслеживает источник событий и регулярно проверяет, есть ли какие-либо события. При необходимости KEDA активирует или деактивирует ваш модуль в зависимости от наличия каких-либо событий, устанавливая значение количества реплик для развертывания равным 1 или 0, в зависимости от вашего минимального количества реплик. KEDA также предоставляет данные о показателях в HPA, который обрабатывает масштабирование до 1 и после него.

- Масштабатор: Подключается к внешнему компоненту (например, ServiceBus) и получает метрики (например, глубину очереди)
- Оператор (агент): Отвечает за “активацию” развертывания и создание объекта автоматического масштабирования горизонтального модуля
- Адаптер метрик: Предоставляет метрики из внешних источников для автоматического масштабирования горизонтального модуля

- KEDA - это тонкий слой, созданный поверх Kubernetes для обеспечения масштабируемой обработки сообщений с использованием функций Azure и других моделей разработки. Это дает вам более точный контроль над операциями масштабирования, которые обычно выполняются за кулисами при запуске функций Azure непосредственно в Azure.
- Хотя KEDA имеет встроенную поддержку первоклассных функций Azure, она не ограничивается функциями Azure. Концепция работает для всех типов приложений, управляемых сообщениями, которые необходимо масштабировать на основе таких показателей, как сообщения в сервисной шине Azure.
- Сокращайте затраты и повышайте скорость реагирования
- Идеально подходит для интенсивных рабочих нагрузок, основанных на событиях
- Работает в облаке и на месте.
What is a good software?
One of answers is doing the right things, with as little cost in operations as possible.
How can we reduce operations costs?
We can use autoscaling
Autoscaling, also known as automatic scaling, is a cloud computing feature that allows you to automatically adjust the capacity of your resources based on actual workload. This capability ensures that you have the right amount of computing resources available to handle varying levels of demand without manual intervention. Auto Scaling is commonly used in cloud environments, like Amazon Web Services (AWS) and Microsoft Azure, to maintain high availability, optimize costs, and improve system performance.
Types of Autoscaling
- Vertical Pod Autoscaling — VPA (Up and Down)
- Horizontal Pod Autoscaling — HPA (Out and In)
- Dynamic Autoscaling
- Predictive Autoscaling
- Event-Driven Autoscaling
Event-Driven Autoscaling
Event-Driven Autoscaling allows you to trigger scaling actions based on specific events or conditions. For example, you can scale your application in response to increased user traffic, the arrival of new data, or the launch of a specific job.
KEDA
KEDA stands for Kubernetes Event-Driven Autoscaling, is an open-source project that provides event-driven auto-scaling for container workloads running on Kubernetes. It enables Kubernetes applications to scale based on external events, such as messages arriving in a queue, the number of HTTP requests, or custom event triggers. KEDA helps make your applications more efficient, cost-effective, and responsive to changes in workloads.
Why Event Driven with KEDA
Kubernetes allows you to autoscale in various ways: horizontally, vertically, or by nodes.
Disadvantages of another solutions
- Supporting only standard Kubernetes objects (deployment, stateful set, replica set) and relying on the metrics server
- There isn’t a way of observing their behavior, so you need to devise your own set of KPIs to see if they’re behaving as expected. So, if HPA or VPA aren’t working as expected for some obscure reason, you won’t receive precise alerts.
- There is not a metric adapter compatible with your data source to build autoscaling rules based on custom metrics. If you have no metric adapter available, you need to stick to resource metrics (CPU or memory).
KEDA vs Traditoinal Autoscalling
Why Event Driven with KEDA
KEDA fills two gaps which you will face while building distributed, cloud-native application at
massive scale.
1. KEDA gives you more control. More control over your instances in contrast to running them
in the public cloud. You can leverage existing Kubernetes cluster and run your, i.e. Azure
Functions, right next to other application building blocks of your overall architecture. KEDA
allows you to specify custom boundaries for scaling behavior.
2. On the other hand, KEDA lets you scale deployments in Kubernetes based on external
events or metrics. In Kubernetes, you can use Horizontal Pod Autoscaler (HPA) to scale
Deployments based on metrics generated inside of the cluster. Especially when running
Kubernetes in combination with external, cloud-based services such as Azure Service Bus,
your application artifacts have to scale on those external metrics.
KEDA provides a structured, streamlined strategy of how to address those needs without adding
much complexity to your overall architecture.
Key Benefits of KEDA
- Efficient Resource Usage
- Event-Driven Architecture
- Cost Optimization with scale-to-zero
- Flexible Integration (50+ scalers)
- Improved Performance
Potential Cost Savings
- Traditional HPA: always keeps minimum pods → higher cost
- KEDA enables idle apps to scale to zero
- Reduces compute resources
- Example: batch processor scaling from 0 to 10 saves up to 70%
KEDA architecture
KEDA monitors your event source and regularly checks if there are any events. When needed, KEDA activates or deactivates your pod depending on whether there are any events by setting the deployment's replica count to 1 or 0, depending on your minimum replica count. KEDA also exposes metrics data to the HPA which handles the scaling to and from 1.
Key components of KEDA
- Scaler: Connects to an external component (e.g., ServiceBus) and fetches metrics (e.g., queue depth)
- Operator (Agent): Responsible for “activating” a Deployment and creating a Horizontal Pod Autoscaler object
- Metrics Adapter: Presents metrics from external sources to the Horizontal Pod Autoscaler
Use Case example. WebApp, ServiceBus, Azure Function
Recap
- KEDA is a thin layer built on top of Kubernetes to allow scalable message processing using Azure Functions and other development models. It gives you more fine-granular control over scale-in and scale-out operations, which generally happen behind the scenes when running Azure Functions directly in Azure.
- Although KEDA has first-class Azure Functions support built-in, it is not limited to Azure Functions. The concept works for all kind of message-driven applications that has to be scaled based on metrics such as messages in an Azure Service Bus.
- Reduce costs, improve responsiveness
- Ideal for bursty, event-based workloads
- Works across cloud and on-prem

 Поделиться
Поделиться




