Публикация была переведена автоматически. Исходный язык: Русский



Когда аналитик открывает таблицу в BI, всё выглядит просто: есть поля, данные сходятся, метрики считаются. Кажется, что цифры просто «где-то лежат» как в Excel, только централизованно. Но под этой видимостью покоя скрывается огромная инженерная работа.
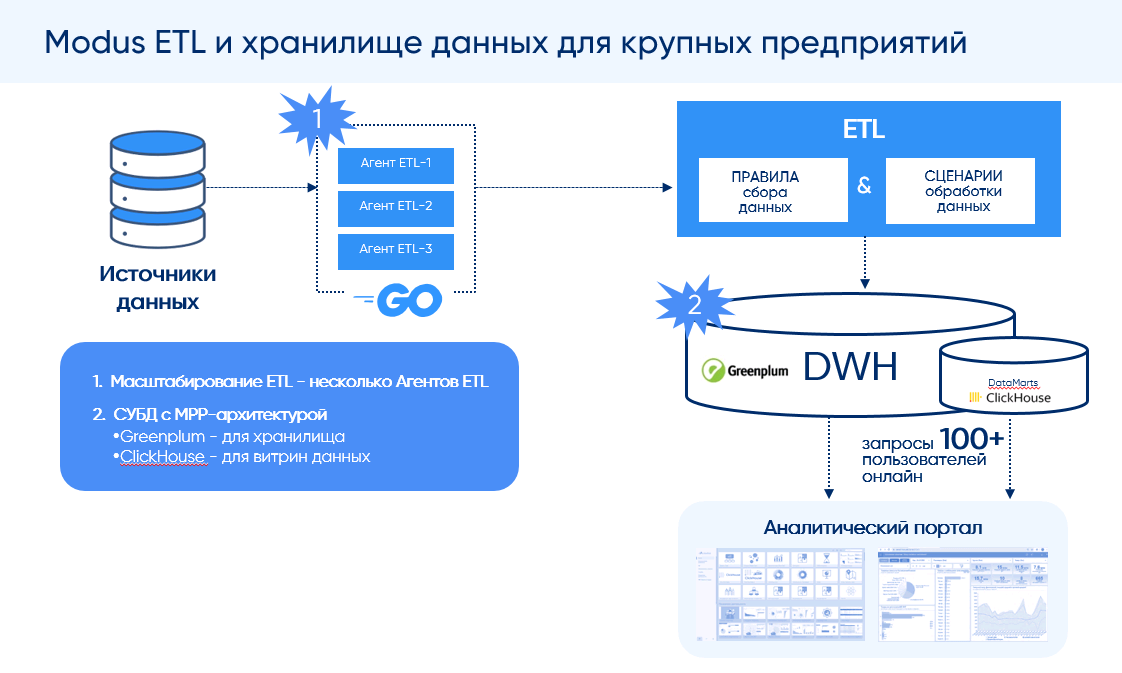
То, что мы называем ETL - Extract, Transform, Load - это сердце любого хранилища данных.
Что такое ETL и зачем он нужен
Если объяснить на человеческом языке, ETL, это процесс превращения сырых, хаотичных данных из разных источников в аккуратную, понятную структуру, с которой уже можно работать аналитически.
Можно сравнить это с кофейней.
У тебя есть поставщики зерна (источники), бариста (инженеры), и клиент, который просто хочет чашку кофе (аналитик).
Клиенту не видно, через сколько стадий обжарки, помола и фильтрации прошли зёрна, но именно это и определяет вкус результата.
Пример : Возьмём интернет-магазин. Данные о заказах приходят из CRM, о клиентах из базы пользователей, о платежах из финансовой системы, а о возвратах из саппорта.
Каждая система живёт в своей логике. В CRM может быть клиент с ID 123, а в платежах тот же человек, но с user_456. В одной таблице даты в формате YYYY-MM-DD, в другой это DD.MM.YYYY. Где-то сумма в евро, где-то в центах, где-то ещё и с налогом.
Теперь представьте: нужно посчитать средний чек за день.
Если просто «склеить всё», результат будет ложным.
И вот здесь вступает в игру ETL.
Extract - Извлечение: На первом этапе данные вытягиваются из всех источников: CRM, ERP, API, логов.
Главная цель, не потерять ничего.
Сырые данные сохраняются в слой staging, без изменений. Это как привезти зерно на склад: грязное, в мешках, но настоящее.
Иногда на этом этапе уже нужно решить, как часто обновлять данные, раз в день, раз в час или в реальном времени. Это вопрос архитектуры: batch или streaming.
Transform - Преобразование: Вот здесь начинается магия. Данные нужно привести к единой структуре, типам и смыслу. Удалить дубли, исправить ошибки, заполнить пропуски, привести валюту, синхронизировать ID между системами. Всё это превращается в серию SQL-запросов, пайплайнов и правил.
Например, чтобы посчитать выручку, нужно объединить заказы и платежи, исключить отменённые, привести всё к евро и округлить до двух знаков. Именно на этом этапе рождаются те самые бизнес-таблицы, с которыми потом работает аналитик.
И если на витрине вы видите красивую колонку revenue_eur, помните: до этого момента данные, возможно, прошли через десятки шагов очистки, маппинга и проверки.
Load - Загрузка: После всех преобразований данные загружаются в витрины данных (Data Marts). Это уже не технические, а аналитические таблицы, каждая из которых отвечает на конкретный вопрос бизнеса.
Например:
📌 dm_orders это все заказы с выручкой и скидками,
📌 dm_customers это клиенты с признаками активности,
📌 dm_marketing это эффективность кампаний и источников.
Это слой, который подключается к BI-инструментам. То, что аналитик открывает как «таблицу с данными», на самом деле, последняя страница длинной инженерной книги.
Как это выглядит в DWH: В хорошем хранилище данных обычно есть три логических слоя:
1. Staging сырые данные из источников, без изменений.
2. Core очищенные, согласованные таблицы (ещё без бизнес-логики).
3. Data Marts витрины под конкретные отчёты, модели и дашборды.
Движение между слоями обеспечивается пайплайнами последовательностями SQL-скриптов, Python-джоб или Airflow-дашбордов. Они выполняются автоматически, например, каждую ночь в 3:00, чтобы утром бизнес получил актуальные цифры.
Почему это важно понимать, также аналитику. Многие аналитики работают “на последней миле” в BI, где уже всё готово. Но если не понимать, как эти данные туда попали, можно сделать красивые, но ложные выводы.
Когда вы знаете, как устроен ETL:
📌 вы задаёте правильные вопросы инженерам;
📌 понимаете, где возможны ошибки в данных;
📌 можете предложить улучшения логики, а не просто отчёт.
И тогда BI перестаёт быть витриной, а становится частью живой системы.
Когда аналитик открывает таблицу в BI, всё выглядит просто: есть поля, данные сходятся, метрики считаются. Кажется, что цифры просто «где-то лежат» как в Excel, только централизованно. Но под этой видимостью покоя скрывается огромная инженерная работа.
То, что мы называем ETL - Extract, Transform, Load - это сердце любого хранилища данных.
Что такое ETL и зачем он нужен
Если объяснить на человеческом языке, ETL, это процесс превращения сырых, хаотичных данных из разных источников в аккуратную, понятную структуру, с которой уже можно работать аналитически.
Можно сравнить это с кофейней.
У тебя есть поставщики зерна (источники), бариста (инженеры), и клиент, который просто хочет чашку кофе (аналитик).
Клиенту не видно, через сколько стадий обжарки, помола и фильтрации прошли зёрна, но именно это и определяет вкус результата.
Пример : Возьмём интернет-магазин. Данные о заказах приходят из CRM, о клиентах из базы пользователей, о платежах из финансовой системы, а о возвратах из саппорта.
Каждая система живёт в своей логике. В CRM может быть клиент с ID 123, а в платежах тот же человек, но с user_456. В одной таблице даты в формате YYYY-MM-DD, в другой это DD.MM.YYYY. Где-то сумма в евро, где-то в центах, где-то ещё и с налогом.
Теперь представьте: нужно посчитать средний чек за день.
Если просто «склеить всё», результат будет ложным.
И вот здесь вступает в игру ETL.
Extract - Извлечение: На первом этапе данные вытягиваются из всех источников: CRM, ERP, API, логов.
Главная цель, не потерять ничего.
Сырые данные сохраняются в слой staging, без изменений. Это как привезти зерно на склад: грязное, в мешках, но настоящее.
Иногда на этом этапе уже нужно решить, как часто обновлять данные, раз в день, раз в час или в реальном времени. Это вопрос архитектуры: batch или streaming.
Transform - Преобразование: Вот здесь начинается магия. Данные нужно привести к единой структуре, типам и смыслу. Удалить дубли, исправить ошибки, заполнить пропуски, привести валюту, синхронизировать ID между системами. Всё это превращается в серию SQL-запросов, пайплайнов и правил.
Например, чтобы посчитать выручку, нужно объединить заказы и платежи, исключить отменённые, привести всё к евро и округлить до двух знаков. Именно на этом этапе рождаются те самые бизнес-таблицы, с которыми потом работает аналитик.
И если на витрине вы видите красивую колонку revenue_eur, помните: до этого момента данные, возможно, прошли через десятки шагов очистки, маппинга и проверки.
Load - Загрузка: После всех преобразований данные загружаются в витрины данных (Data Marts). Это уже не технические, а аналитические таблицы, каждая из которых отвечает на конкретный вопрос бизнеса.
Например:
📌 dm_orders это все заказы с выручкой и скидками,
📌 dm_customers это клиенты с признаками активности,
📌 dm_marketing это эффективность кампаний и источников.
Это слой, который подключается к BI-инструментам. То, что аналитик открывает как «таблицу с данными», на самом деле, последняя страница длинной инженерной книги.
Как это выглядит в DWH: В хорошем хранилище данных обычно есть три логических слоя:
1. Staging сырые данные из источников, без изменений.
2. Core очищенные, согласованные таблицы (ещё без бизнес-логики).
3. Data Marts витрины под конкретные отчёты, модели и дашборды.
Движение между слоями обеспечивается пайплайнами последовательностями SQL-скриптов, Python-джоб или Airflow-дашбордов. Они выполняются автоматически, например, каждую ночь в 3:00, чтобы утром бизнес получил актуальные цифры.
Почему это важно понимать, также аналитику. Многие аналитики работают “на последней миле” в BI, где уже всё готово. Но если не понимать, как эти данные туда попали, можно сделать красивые, но ложные выводы.
Когда вы знаете, как устроен ETL:
📌 вы задаёте правильные вопросы инженерам;
📌 понимаете, где возможны ошибки в данных;
📌 можете предложить улучшения логики, а не просто отчёт.
И тогда BI перестаёт быть витриной, а становится частью живой системы.
 Поделиться
Поделиться