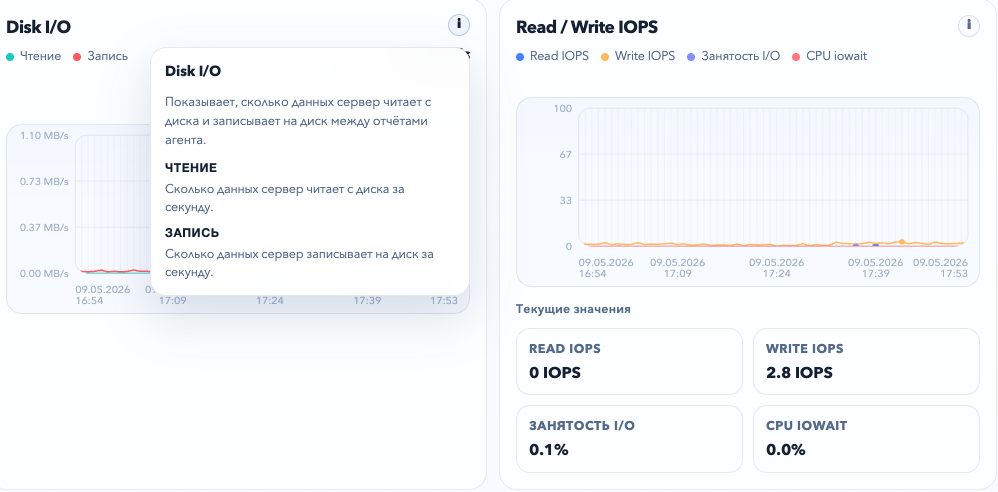
Публикация была переведена автоматически. Исходный язык: Русский



Личное наблюдение, большинство систем мониторинга начинают одинаково.
Настроили ping. Поставили проверку сайта. Увидели зеленую галочку. Успокоились.
Мы тоже так работали много лет.
И именно поэтому регулярно сталкивались с ситуацией, когда “мониторинг ничего не показывал”, но проблема уже существовала.
Сайт вроде открывается. Сервер отвечает. Ping проходит.
Но:
- система начинает тормозить
- клиенты жалуются на скорость
- часть сервисов работает нестабильно
- SSL скоро заканчивается
- домен вот-вот истечет
- ночью что-то ломается, а узнаешь об этом только утром
В какой-то момент стало очевидно: современной инфраструктуре уже недостаточно просто проверять доступность сайта.
Pinguva появилась именно из этой боли.
Не как “еще один uptime checker”. А как попытка создать мониторинг, который предупреждает о проблеме до того, как она становится критичной для бизнеса.
Почему обычного ping уже недостаточно
Одна из главных проблем инфраструктуры в том, что большинство сбоев происходят не мгновенно.
Очень редко сервер просто “умирает” за секунду.
Чаще все происходит постепенно:
- сервисы начинают работать медленнее
- растет нагрузка
- появляются задержки
- инфраструктура деградирует шаг за шагом
При этом сайт может продолжать открываться. А ping продолжает отвечать.
Снаружи все выглядит нормально. Но внутри проблема уже развивается.
Именно такие ситуации самые опасные. Потому что бизнес еще не понимает, что происходит, а пользователи уже начинают сталкиваться с последствиями.
Мы сталкивались с этим постоянно. Особенно ночью. Особенно на проектах с высокой нагрузкой и большим количеством сервисов.
Почему мы сделали акцент на простоте
Еще одна вещь, которая нас всегда раздражала в системах мониторинга - сложное подключение.
Очень часто внедрение выглядит как отдельный инфраструктурный проект:
- настройка VPN
- проброс портов
- firewall rules
- сложные схемы доступа
- длительная настройка агентов
В реальности многим компаниям нужен другой подход.
Чтобы мониторинг можно было подключить быстро. Без сложной сетевой архитектуры. Без необходимости открывать сервер наружу.
Поэтому в Pinguva мы изначально пошли по пути: максимально простое подключение агента одной командой.
Без проброса портов. Без VPN между серверами. Без сложной подготовки инфраструктуры.
Потому что хороший мониторинг должен экономить время, а не создавать новую головную боль.
Почему мониторинг - это уже не только про серверы
Со временем мы поняли еще одну важную вещь.
Для бизнеса не имеет значения, где именно произошла проблема.
Пользователь не думает: “у нас истек SSL-сертификат” или “у нас проблемы с DNS”.
Для него все выглядит одинаково: “сайт не работает”.
Поэтому современный мониторинг должен смотреть шире.
Не только:
- отвечает ли сервер
- открыт ли порт
Но и:
- не заканчивается ли SSL
- не истекает ли домен
- корректно ли работает HTTPS
- доступны ли ключевые сервисы
- нет ли признаков деградации системы
И желательно - заранее.
Что мы поняли во время разработки Pinguva
Самая большая проблема мониторинга сегодня - не отсутствие данных.
Наоборот. Данных слишком много.
Графики. Метрики. Логи. Уведомления. Десятки экранов.
Но в критический момент инженеру нужен ответ только на один вопрос: “Что именно сейчас идет не так?”
Поэтому один из главных принципов Pinguva: меньше шума - больше ясности.
Мы хотим, чтобы система помогала увидеть проблему раньше пользователя и быстрее понять ее причину.
Собственно, из этой идеи Pinguva и выросла, надеемся что она будет полезна.
Личное наблюдение, большинство систем мониторинга начинают одинаково.
Настроили ping. Поставили проверку сайта. Увидели зеленую галочку. Успокоились.
Мы тоже так работали много лет.
И именно поэтому регулярно сталкивались с ситуацией, когда “мониторинг ничего не показывал”, но проблема уже существовала.
Сайт вроде открывается. Сервер отвечает. Ping проходит.
Но:
- система начинает тормозить
- клиенты жалуются на скорость
- часть сервисов работает нестабильно
- SSL скоро заканчивается
- домен вот-вот истечет
- ночью что-то ломается, а узнаешь об этом только утром
В какой-то момент стало очевидно: современной инфраструктуре уже недостаточно просто проверять доступность сайта.
Pinguva появилась именно из этой боли.
Не как “еще один uptime checker”. А как попытка создать мониторинг, который предупреждает о проблеме до того, как она становится критичной для бизнеса.
Почему обычного ping уже недостаточно
Одна из главных проблем инфраструктуры в том, что большинство сбоев происходят не мгновенно.
Очень редко сервер просто “умирает” за секунду.
Чаще все происходит постепенно:
- сервисы начинают работать медленнее
- растет нагрузка
- появляются задержки
- инфраструктура деградирует шаг за шагом
При этом сайт может продолжать открываться. А ping продолжает отвечать.
Снаружи все выглядит нормально. Но внутри проблема уже развивается.
Именно такие ситуации самые опасные. Потому что бизнес еще не понимает, что происходит, а пользователи уже начинают сталкиваться с последствиями.
Мы сталкивались с этим постоянно. Особенно ночью. Особенно на проектах с высокой нагрузкой и большим количеством сервисов.
Почему мы сделали акцент на простоте
Еще одна вещь, которая нас всегда раздражала в системах мониторинга - сложное подключение.
Очень часто внедрение выглядит как отдельный инфраструктурный проект:
- настройка VPN
- проброс портов
- firewall rules
- сложные схемы доступа
- длительная настройка агентов
В реальности многим компаниям нужен другой подход.
Чтобы мониторинг можно было подключить быстро. Без сложной сетевой архитектуры. Без необходимости открывать сервер наружу.
Поэтому в Pinguva мы изначально пошли по пути: максимально простое подключение агента одной командой.
Без проброса портов. Без VPN между серверами. Без сложной подготовки инфраструктуры.
Потому что хороший мониторинг должен экономить время, а не создавать новую головную боль.
Почему мониторинг - это уже не только про серверы
Со временем мы поняли еще одну важную вещь.
Для бизнеса не имеет значения, где именно произошла проблема.
Пользователь не думает: “у нас истек SSL-сертификат” или “у нас проблемы с DNS”.
Для него все выглядит одинаково: “сайт не работает”.
Поэтому современный мониторинг должен смотреть шире.
Не только:
- отвечает ли сервер
- открыт ли порт
Но и:
- не заканчивается ли SSL
- не истекает ли домен
- корректно ли работает HTTPS
- доступны ли ключевые сервисы
- нет ли признаков деградации системы
И желательно - заранее.
Что мы поняли во время разработки Pinguva
Самая большая проблема мониторинга сегодня - не отсутствие данных.
Наоборот. Данных слишком много.
Графики. Метрики. Логи. Уведомления. Десятки экранов.
Но в критический момент инженеру нужен ответ только на один вопрос: “Что именно сейчас идет не так?”
Поэтому один из главных принципов Pinguva: меньше шума - больше ясности.
Мы хотим, чтобы система помогала увидеть проблему раньше пользователя и быстрее понять ее причину.
Собственно, из этой идеи Pinguva и выросла, надеемся что она будет полезна.

 Поделиться
Поделиться




