Публикация была переведена автоматически. Исходный язык: Русский


Когда говорят "мобильное приложение с сервером", почти всегда разговор уходит в три темы: авторизация, платежи, push-уведомления. Синхронизацию данных как будто стыдливо оставляют за кадром, в стиле "ну там просто REST, JSON и локальная база".
А потом вдруг оказывается, что самое сложное в продукте - не экран с анимацией, не OAuth, не красивые графики, а банальное "чтобы у пользователя на всех устройствах всё совпадало, и оффлайн тоже работал".
Этот пост как раз про это. Про ту часть разработки, где ты уже давно понимаешь, как работать с HTTP, WebSocket, JWT и прочим, но при этом всё равно сидишь ночью и смотришь в diff двух записей "одного и того же" объекта и не можешь ответить на простой вопрос:
- И кто тут прав?
Так это обычно звучит в самом начале:
- Давайте сделаем оффлайн, чтобы всё работало без интернета
- И чтобы оно потом само синхронизировалось, когда сеть появится
- И чтобы на всех устройствах всё было одинаково
На слайдах это выглядит красиво:
телефон что-то пишет в локальную базу, потом отправляет на сервер, сервер всё хранит, другие устройства подтягивают свежие данные.
В какой-то момент ты понимаешь, что внутри этой стрелочки "потом отправляет на сервер" спрятано примерно половина всей сложности системы.
На демо всё просто:
- пользователь открыл приложение
- что-то сделал
- интернет был
- запрос ушёл, ответ пришёл, все счастливы
Но реальный пользователь живёт иначе:
- он едет в метро, где интернет то есть, то нет
- он открывает приложение, что-то меняет, сворачивает, OS его убивает
- у него два устройства, и он на обоих что-то редактирует, пока сеть "залипает" где-то между вышками
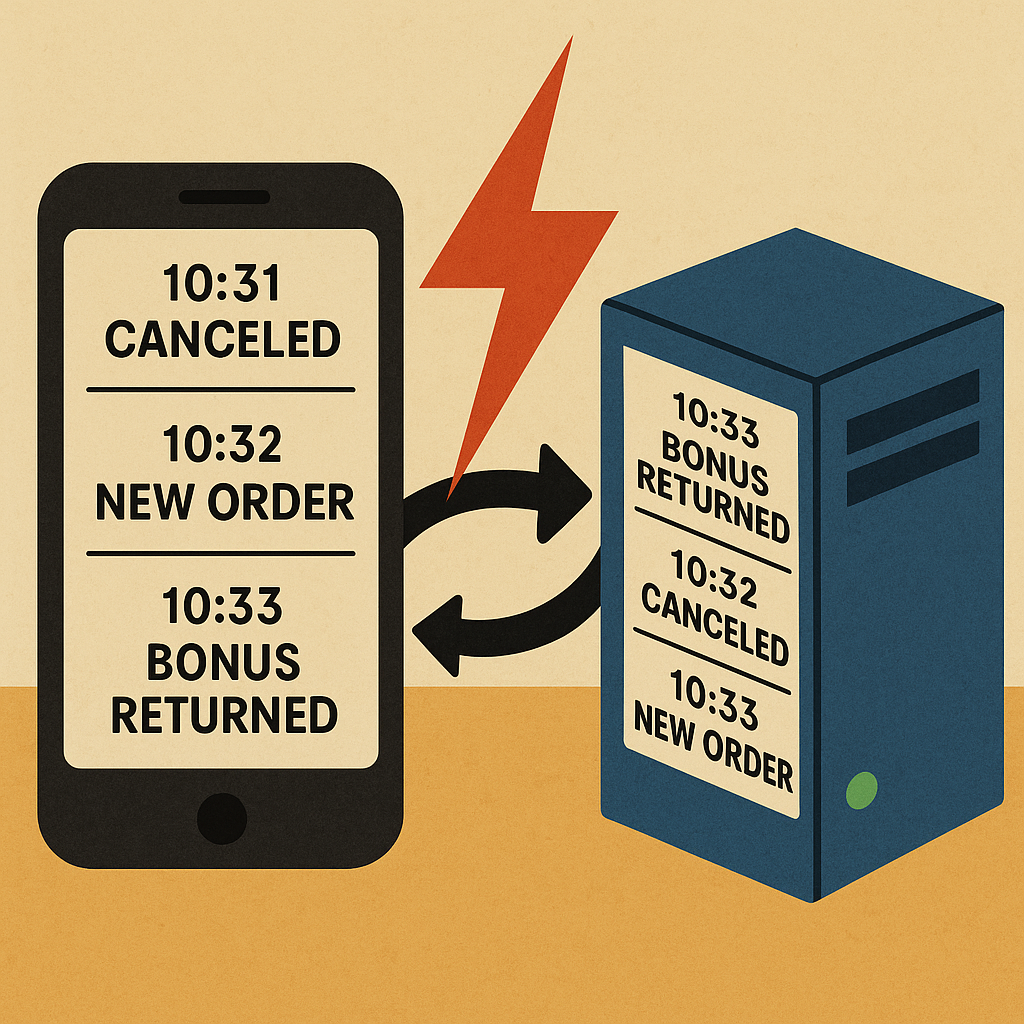
И вот у тебя в базе на сервере лежит одна версия сущности, в телефоне первая - другая, во втором телефоне - третья, а в очереди сообщений между ними ещё какая-то промежуточная.
И продукт на полном серьёзе спрашивает:
- Ну у нас же есть updated_at, давайте по нему возьмем свежую и всё?
Самое первое, что делают почти все (мы тоже делали) - стратегию last write wins:
- у каждой записи есть поле updated_at
- на сервер прилетает изменение - мы просто сравниваем, что новее
- более новая версия затирает старую
На бумаге - идеально. В жизни - нет.
Простой пример из практики:
- У пользователя на телефоне A открыт экран профиля, он меняет, допустим, имя.
- У него плохой интернет, запрос подвис, приложение ушло в фон, OS его выгрузила.
- Пользователь берёт телефон B, где ещё старая версия данных, и меняет там, допустим, только аватар. Там интернет норм, аватар улетает и сохраняется на сервере.
- Через некоторое время первый телефон “просыпается”, пытается дослать своё изменение имени, и сервер получает старый снимок профиля, но с новым временем.
Если у тебя простая модель последний победил - в этот момент ты аккуратно затираешь новый аватар старым, потому что эта запись же более свежая. Для пользователя это выглядит как магическое откатывание изменений.
И что ты ему скажешь?
- Извините, так вышло, у нас там стратегия разрешения конфликтов без мозгов?
Следующая ступень эволюции:
- Ну давайте тогда не затирать, а сливать поле за полем.
Логика примерно такая:
- приходящую с клиента сущность мы сравниваем с текущей на сервере
- смотрим, какие поля реально изменились
- пытемся аккуратно слить это с тем, что есть
Звучит разумно. Мы тоже так сделали.
Дальше начинается интересное.
Условный пример, упрощенный до боли:
// было в базе
{
"name": "Анна",
"city": "Berlin",
"tags": ["vip", "beta"]
}Телефон A меняет city на Munich.
Телефон B в это время в оффлайне удаляет из tags beta и добавляет promo.
Если делать умный merge:
- берем старую версию как базу
- вмердживаем новый city
- аккуратно применяем diff по tags, который прислал второй клиент
Звучит красиво, но реализация очень быстро превращается в маленький ад:
- нужно уметь считать диффы не только для простых полей, но и для массивов, вложенных структур;
- нужно понимать, какие поля трудно конфликтующие (например, баланс денег) и не пытаться их мержить по частям;
- нужно решать, что делать, если оба клиента поменяли одно и то же поле по-разному - и нет, там далеко не всегда очевиден правильный ответ.
В какой-то момент ты смотришь на свой код мержинга и понимаешь, что написал маленький велосипедный CRDT, только без формальной модели и с кучей эвристик на if-ах.
Сервисная часть ещё как-то спокойно живёт с очередями, ретраями, журналами изменений.
Мобильная - нет.
У тебя, по сути, есть две большие проблемы:
- OS не обещает тебе, что фоновые задачи доживут до конца синхронизации.
- OS не обязана давать тебе фон добрыми порциями когда удобно разработчику.
Упрощенно:
- на iOS у тебя ограниченное время на фоновые задачи, и система в любой момент может сказать "всё, хватит, спи";
- на Android у тебя Doze, ограничения на будильники, оптимизация батареи от вендора, которая внезапно убивает всё живое.
В результате очень обычная ситуация:
- ты начал отправлять пачку изменений с устройства на сервер;
- успел отправить половину;
- фон отрубили;
- часть изменений в очереди осталась локально;
- интернет тогда был кривой, позже стал нормальный, но приложение уже выгружено.
Если ты не построил нормальный журнал событий на устройстве, который переживает такие истории, ты получишь дыры в данных. И дальше никакой last write wins и merge по полям уже не спасает, потому что у сервера просто нет полного контекста.
Очень популярная мантра: сервер - источник истины.
Она звучит красиво, пока ты не начинаешь разбирать реальные кейсы.
Например:
- пользователь что-то поменял оффлайн;
- на сервере ещё старая версия;
- пользователь смотрит на экран и видит новую информацию;
- через какое-то время приложение обновляет данные с сервера;
- если ты бездумно перезаписываешь локальное состояние серверным - ты только что откатил изменения, о которых сервер не знал.
Получается забавный эффект:
сервер честно хранит то, что в него пришло,
клиент честно хранит то, что ввёл пользователь,
а пользователь всё равно получает ощущение, что приложение живёт своей жизнью и всё само меняет.
В какой-то момент мы перестали относиться к слову синхронизация как к чему-то вторичному.
Оказалось, что если:
- не договориться с продуктовой командой, какой именно сценарий важнее (последний выиграл, каждый девайс прав, сервер прав и т.д.),
- не договориться, какие поля мержим, а какие считаем атомарными,
- не придумать честную модель конфликтов, в которой можно объяснить, что произошло,
то дальше уже не важно, какой там протокол, язык, фреймворки. Пользователь будет видеть внезапно исчезающие данные, само вернувшиеся значения, странные скачки в списках.
Самое неприятное, что чем дальше ты идёшь, тем меньше это похоже на техническую проблему. У тебя появляются вопросы типа:
- А если пользователь редактировал заметку на двух устройствах одновременно - кто из них выигрывает?
- А если человек вписал новый адрес, а потом на другом девайсе удалил весь профиль - мы вообще имеем право попытаться "умно" склеить это?
- А если у нас юридически значимый документ - мы имеем право делать хоть какой-то автоматический merge?
И ты понимаешь, что в нужный момент никого не интересует, что у тебя там на сервере был RabbitMQ, а на клиенте Room/Realm/CoreData. Всех интересует только одно:
- почему у меня вот здесь было так, а стало вот так?
Из того, что реально снизило количество магических багов:
- Перестать думать про один источник правды и честно нарисовать несколько:что видит пользователь прямо сейчасчто сейчас лежит на серверечто было в юридически значимых записях
- что видит пользователь прямо сейчас
- что сейчас лежит на сервере
- что было в юридически значимых записях
- Явно маркировать записи на клиенте:это чисто локальные изменения, ещё не дошли до сервераэто данные, которые уже подтверждены сервером
- это чисто локальные изменения, ещё не дошли до сервера
- это данные, которые уже подтверждены сервером
- Делать не синхронизацию, а репликацию:то есть не думаем записать правильное состояние, а думаем переигрываем последовательность событий, чтобы прийти к одному состоянию
- то есть не думаем записать правильное состояние, а думаем переигрываем последовательность событий, чтобы прийти к одному состоянию
Интересный побочный эффект: часть магии ушла из UI. Вместо того чтобы пытаться спрятать все швы, мы начали честно показывать пользователю:
- что какие-то изменения ещё в пути;
- что в конфликтных ситуациях последнее решение всё равно за ним (например, дать выбрать версию записи).
А что не сработало - это любые попытки решить всё одним флагом:
- давайте по updated_at
- давайте сервер всегда прав
- давайте клиент всегда прав
- давайте просто отрубим оффлайн
Все эти фразы красиво звучат на встрече, но очень плохо живут в поле, когда появляются живые пользователи, плохой интернет и люди, у которых на одном аккаунте три устройства.
Про это редко пишут в формате красивых кейсов. Про push’и пишут, про мы перешли на новый стек пишут, про мы внедрили CI/CD пишут.
А вот про то, как ты три месяца подряд рассматриваешь логи вида:
"prev_version": { ... },
"incoming_version": { ... },
"merged_version": { ... }и споришь с тем-лидом, какое именно поведение считать "нормальным" - про это как-то не очень принято рассказывать. Потому что это не продаётся как "инновация". Это просто то, без чего любая крутая мобильная платформа через какое-то время начинает тухнуть изнутри.
Но если посмотреть на реально живые продукты, которые много лет живут на рынке и у которых есть оффлайн, несколько устройств, сложные данные - почти всегда под капотом там лежат не просто REST и база, а аккуратно прожёванный, переписанный несколько раз ад с версионированием, конфликтами, очередями и вопросами кто в этой ситуации прав.
И вот это как раз та часть разработки, до которой нельзя додуматься на бумаге. До неё докапываются именно теми самыми тысячами часов, логами, дебагами на живых данных и редкими, но очень запоминающимися разговорами с пользователями и поддержкой.
Когда говорят "мобильное приложение с сервером", почти всегда разговор уходит в три темы: авторизация, платежи, push-уведомления. Синхронизацию данных как будто стыдливо оставляют за кадром, в стиле "ну там просто REST, JSON и локальная база".
А потом вдруг оказывается, что самое сложное в продукте - не экран с анимацией, не OAuth, не красивые графики, а банальное "чтобы у пользователя на всех устройствах всё совпадало, и оффлайн тоже работал".
Этот пост как раз про это. Про ту часть разработки, где ты уже давно понимаешь, как работать с HTTP, WebSocket, JWT и прочим, но при этом всё равно сидишь ночью и смотришь в diff двух записей "одного и того же" объекта и не можешь ответить на простой вопрос:
- И кто тут прав?
Так это обычно звучит в самом начале:
- Давайте сделаем оффлайн, чтобы всё работало без интернета
- И чтобы оно потом само синхронизировалось, когда сеть появится
- И чтобы на всех устройствах всё было одинаково
На слайдах это выглядит красиво:
телефон что-то пишет в локальную базу, потом отправляет на сервер, сервер всё хранит, другие устройства подтягивают свежие данные.
В какой-то момент ты понимаешь, что внутри этой стрелочки "потом отправляет на сервер" спрятано примерно половина всей сложности системы.
На демо всё просто:
- пользователь открыл приложение
- что-то сделал
- интернет был
- запрос ушёл, ответ пришёл, все счастливы
Но реальный пользователь живёт иначе:
- он едет в метро, где интернет то есть, то нет
- он открывает приложение, что-то меняет, сворачивает, OS его убивает
- у него два устройства, и он на обоих что-то редактирует, пока сеть "залипает" где-то между вышками
И вот у тебя в базе на сервере лежит одна версия сущности, в телефоне первая - другая, во втором телефоне - третья, а в очереди сообщений между ними ещё какая-то промежуточная.
И продукт на полном серьёзе спрашивает:
- Ну у нас же есть updated_at, давайте по нему возьмем свежую и всё?
Самое первое, что делают почти все (мы тоже делали) - стратегию last write wins:
- у каждой записи есть поле updated_at
- на сервер прилетает изменение - мы просто сравниваем, что новее
- более новая версия затирает старую
На бумаге - идеально. В жизни - нет.
Простой пример из практики:
- У пользователя на телефоне A открыт экран профиля, он меняет, допустим, имя.
- У него плохой интернет, запрос подвис, приложение ушло в фон, OS его выгрузила.
- Пользователь берёт телефон B, где ещё старая версия данных, и меняет там, допустим, только аватар. Там интернет норм, аватар улетает и сохраняется на сервере.
- Через некоторое время первый телефон “просыпается”, пытается дослать своё изменение имени, и сервер получает старый снимок профиля, но с новым временем.
Если у тебя простая модель последний победил - в этот момент ты аккуратно затираешь новый аватар старым, потому что эта запись же более свежая. Для пользователя это выглядит как магическое откатывание изменений.
И что ты ему скажешь?
- Извините, так вышло, у нас там стратегия разрешения конфликтов без мозгов?
Следующая ступень эволюции:
- Ну давайте тогда не затирать, а сливать поле за полем.
Логика примерно такая:
- приходящую с клиента сущность мы сравниваем с текущей на сервере
- смотрим, какие поля реально изменились
- пытемся аккуратно слить это с тем, что есть
Звучит разумно. Мы тоже так сделали.
Дальше начинается интересное.
Условный пример, упрощенный до боли:
// было в базе
{
"name": "Анна",
"city": "Berlin",
"tags": ["vip", "beta"]
}Телефон A меняет city на Munich.
Телефон B в это время в оффлайне удаляет из tags beta и добавляет promo.
Если делать умный merge:
- берем старую версию как базу
- вмердживаем новый city
- аккуратно применяем diff по tags, который прислал второй клиент
Звучит красиво, но реализация очень быстро превращается в маленький ад:
- нужно уметь считать диффы не только для простых полей, но и для массивов, вложенных структур;
- нужно понимать, какие поля трудно конфликтующие (например, баланс денег) и не пытаться их мержить по частям;
- нужно решать, что делать, если оба клиента поменяли одно и то же поле по-разному - и нет, там далеко не всегда очевиден правильный ответ.
В какой-то момент ты смотришь на свой код мержинга и понимаешь, что написал маленький велосипедный CRDT, только без формальной модели и с кучей эвристик на if-ах.
Сервисная часть ещё как-то спокойно живёт с очередями, ретраями, журналами изменений.
Мобильная - нет.
У тебя, по сути, есть две большие проблемы:
- OS не обещает тебе, что фоновые задачи доживут до конца синхронизации.
- OS не обязана давать тебе фон добрыми порциями когда удобно разработчику.
Упрощенно:
- на iOS у тебя ограниченное время на фоновые задачи, и система в любой момент может сказать "всё, хватит, спи";
- на Android у тебя Doze, ограничения на будильники, оптимизация батареи от вендора, которая внезапно убивает всё живое.
В результате очень обычная ситуация:
- ты начал отправлять пачку изменений с устройства на сервер;
- успел отправить половину;
- фон отрубили;
- часть изменений в очереди осталась локально;
- интернет тогда был кривой, позже стал нормальный, но приложение уже выгружено.
Если ты не построил нормальный журнал событий на устройстве, который переживает такие истории, ты получишь дыры в данных. И дальше никакой last write wins и merge по полям уже не спасает, потому что у сервера просто нет полного контекста.
Очень популярная мантра: сервер - источник истины.
Она звучит красиво, пока ты не начинаешь разбирать реальные кейсы.
Например:
- пользователь что-то поменял оффлайн;
- на сервере ещё старая версия;
- пользователь смотрит на экран и видит новую информацию;
- через какое-то время приложение обновляет данные с сервера;
- если ты бездумно перезаписываешь локальное состояние серверным - ты только что откатил изменения, о которых сервер не знал.
Получается забавный эффект:
сервер честно хранит то, что в него пришло,
клиент честно хранит то, что ввёл пользователь,
а пользователь всё равно получает ощущение, что приложение живёт своей жизнью и всё само меняет.
В какой-то момент мы перестали относиться к слову синхронизация как к чему-то вторичному.
Оказалось, что если:
- не договориться с продуктовой командой, какой именно сценарий важнее (последний выиграл, каждый девайс прав, сервер прав и т.д.),
- не договориться, какие поля мержим, а какие считаем атомарными,
- не придумать честную модель конфликтов, в которой можно объяснить, что произошло,
то дальше уже не важно, какой там протокол, язык, фреймворки. Пользователь будет видеть внезапно исчезающие данные, само вернувшиеся значения, странные скачки в списках.
Самое неприятное, что чем дальше ты идёшь, тем меньше это похоже на техническую проблему. У тебя появляются вопросы типа:
- А если пользователь редактировал заметку на двух устройствах одновременно - кто из них выигрывает?
- А если человек вписал новый адрес, а потом на другом девайсе удалил весь профиль - мы вообще имеем право попытаться "умно" склеить это?
- А если у нас юридически значимый документ - мы имеем право делать хоть какой-то автоматический merge?
И ты понимаешь, что в нужный момент никого не интересует, что у тебя там на сервере был RabbitMQ, а на клиенте Room/Realm/CoreData. Всех интересует только одно:
- почему у меня вот здесь было так, а стало вот так?
Из того, что реально снизило количество магических багов:
- Перестать думать про один источник правды и честно нарисовать несколько:что видит пользователь прямо сейчасчто сейчас лежит на серверечто было в юридически значимых записях
- что видит пользователь прямо сейчас
- что сейчас лежит на сервере
- что было в юридически значимых записях
- Явно маркировать записи на клиенте:это чисто локальные изменения, ещё не дошли до сервераэто данные, которые уже подтверждены сервером
- это чисто локальные изменения, ещё не дошли до сервера
- это данные, которые уже подтверждены сервером
- Делать не синхронизацию, а репликацию:то есть не думаем записать правильное состояние, а думаем переигрываем последовательность событий, чтобы прийти к одному состоянию
- то есть не думаем записать правильное состояние, а думаем переигрываем последовательность событий, чтобы прийти к одному состоянию
Интересный побочный эффект: часть магии ушла из UI. Вместо того чтобы пытаться спрятать все швы, мы начали честно показывать пользователю:
- что какие-то изменения ещё в пути;
- что в конфликтных ситуациях последнее решение всё равно за ним (например, дать выбрать версию записи).
А что не сработало - это любые попытки решить всё одним флагом:
- давайте по updated_at
- давайте сервер всегда прав
- давайте клиент всегда прав
- давайте просто отрубим оффлайн
Все эти фразы красиво звучат на встрече, но очень плохо живут в поле, когда появляются живые пользователи, плохой интернет и люди, у которых на одном аккаунте три устройства.
Про это редко пишут в формате красивых кейсов. Про push’и пишут, про мы перешли на новый стек пишут, про мы внедрили CI/CD пишут.
А вот про то, как ты три месяца подряд рассматриваешь логи вида:
"prev_version": { ... },
"incoming_version": { ... },
"merged_version": { ... }и споришь с тем-лидом, какое именно поведение считать "нормальным" - про это как-то не очень принято рассказывать. Потому что это не продаётся как "инновация". Это просто то, без чего любая крутая мобильная платформа через какое-то время начинает тухнуть изнутри.
Но если посмотреть на реально живые продукты, которые много лет живут на рынке и у которых есть оффлайн, несколько устройств, сложные данные - почти всегда под капотом там лежат не просто REST и база, а аккуратно прожёванный, переписанный несколько раз ад с версионированием, конфликтами, очередями и вопросами кто в этой ситуации прав.
И вот это как раз та часть разработки, до которой нельзя додуматься на бумаге. До неё докапываются именно теми самыми тысячами часов, логами, дебагами на живых данных и редкими, но очень запоминающимися разговорами с пользователями и поддержкой.

 Поделиться
Поделиться