Публикация была переведена автоматически. Исходный язык: Русский



Когда передо мной встала задача добавить ИИ-поиск по большому книжному каталогу, первый порыв был — взять Pinecone или Qdrant. Потом мы осмотрелись: PostgreSQL уже стоит, Docker уже настроен, pgvector уже есть в экосистеме. Зачем плодить еще одну векторную БД решил я.
Что такое RAG и зачем это нужно
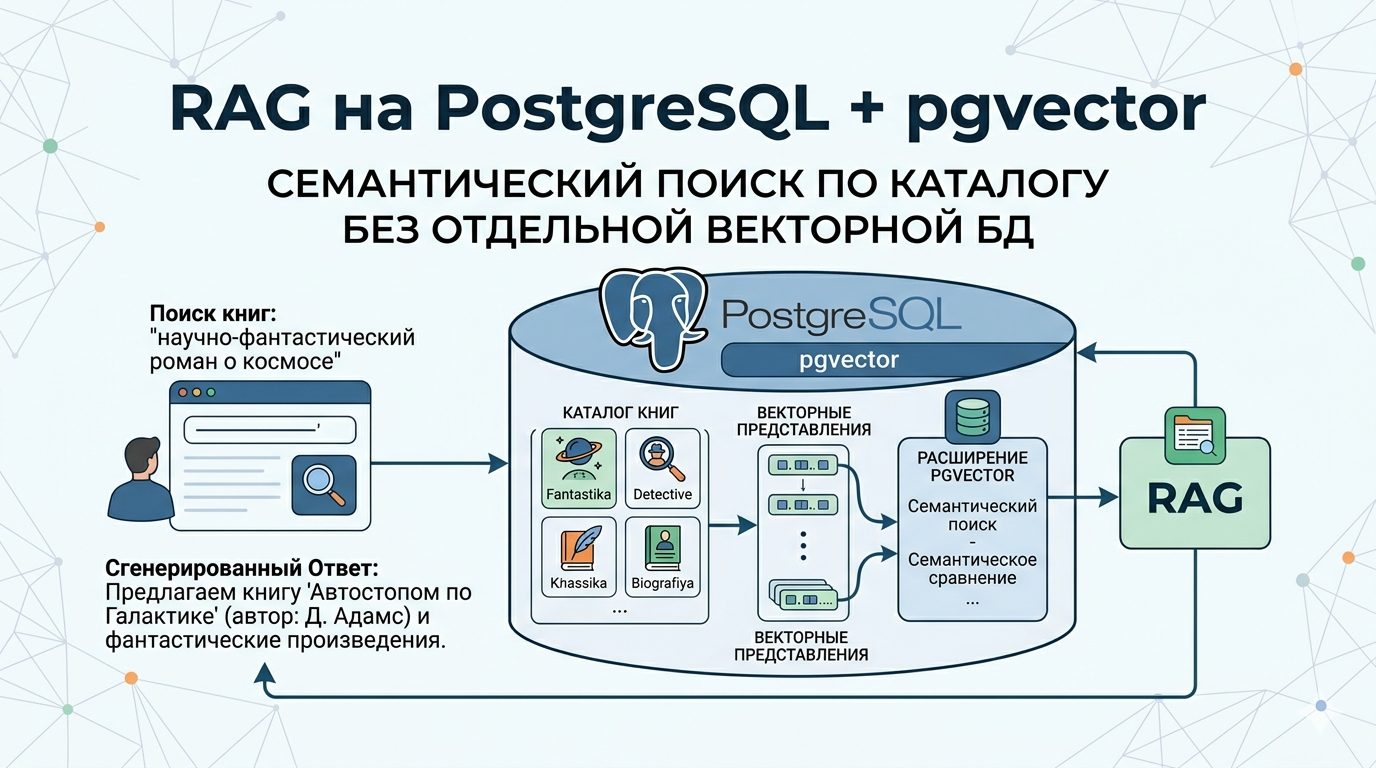
RAG (Retrieval-Augmented Generation) — архитектурный паттерн, при котором языковая модель перед ответом получает релевантный контекст из базы данных. Вместо того чтобы «придумывать» ответ, модель опирается на реальные данные из базы. Для книжного каталога это означает следующее: пользователь пишет «есть ли у вас книги про машинное обучение на казахском?» — и система находит релевантные записи семантически, а не по точному совпадению ключевых слов. Получаем на выходе реальный «умный поиск»: пользователи ищут разными словами одно и то же понятие и такой способ позволяет осуществлять релевантный поиск.
Архитектура пайплайна будет стакой:
Индексация Документы / каталог → OpenAI Embeddings → pgvector (PostgreSQL)
Запрос Вопрос пользователя → Embed запроса → Similarity search → Claude / GPT → ответ
Шаг 1. Включаем pgvector
Если у вас уже есть PostgreSQL, тогда нужно просто добавить pgvector одной строкой в SQL:
-- Включаем расширение в нужной базе данных
CREATE EXTENSION IF NOT EXISTS vector;
-- Проверяем версию
SELECT extname, extversion FROM pg_extension
WHERE extname = 'vector';
-- extname | extversion
-- vector | 0.8.2Для докера есть готовый образ с уже встроенным pgvector:
# docker-compose.yml
services:
db:
image: pgvector/pgvector:pg16
environment:
POSTGRES_DB: library_rag
POSTGRES_USER: app
POSTGRES_PASSWORD: secret
volumes:
- pgdata:/var/lib/postgresql/dataДля standalone версии PostgreSQL на Ubuntu/Debian ставим: sudo apt install postgresql-16-pgvector.
Расширение живёт рядом с остальными данными и не требует пересборки или миграции существующих таблиц.
Шаг 2. Схема таблицы
Создаём таблицу для записей каталога. Колонка embedding хранит вектор размерностью 1536 — это стандарт модели text-embedding-3-small от OpenAI:
CREATE TABLE catalog_chunks (
id BIGSERIAL PRIMARY KEY,
document_id TEXT NOT NULL, -- ISBN или внутренний ID
title TEXT,
content TEXT NOT NULL, -- текстовый чанк
language TEXT DEFAULT 'ru',
metadata JSONB, -- автор, год, УДК и т.д.
embedding vector(1536), -- OpenAI text-embedding-3-small
created_at TIMESTAMP DEFAULT NOW()
);
-- HNSW-индекс — стандарт де-факто в 2026 году
-- Лучше IVFFlat: можно создать до загрузки данных,
-- выше recall, ниже latency при поиске
CREATE INDEX catalog_embedding_hnsw_idx
ON catalog_chunks
USING hnsw (embedding vector_cosine_ops)
WITH (m = 16, ef_construction = 64);Шаг 3. Индексация — загружаем каталог
Python-скрипт берёт записи из каталога, отправляет текст в OpenAI Embeddings API и сохраняет векторы в PostgreSQL:
import psycopg2
from openai import OpenAI
import hashlib
client = OpenAI() # читает OPENAI_API_KEY из env
def get_embedding(text: str) -> list[float]:
"""Получить вектор для текста через OpenAI API."""
response = client.embeddings.create(
model="text-embedding-3-small", # 1536 dim, $0.02/1M токенов
input=text.replace("\n", " ")
)
return response.data[0].embedding
def index_book(conn, book: dict):
"""Индексировать одну книгу из каталога."""
text = f"{book['title']} {book['author']} {book['description']}"
with conn.cursor() as cur:
# Пропускаем если запись уже есть
cur.execute(
"SELECT id FROM catalog_chunks WHERE document_id=%s",
(book['isbn'],)
)
if cur.fetchone():
return
embedding = get_embedding(text)
cur.execute("""
INSERT INTO catalog_chunks
(document_id, title, content, language, metadata, embedding)
VALUES (%s, %s, %s, %s, %s, %s)
""", (
book['isbn'], book['title'], text,
book.get('lang', 'ru'),
psycopg2.extras.Json({'author': book['author'], 'year': book['year']}),
embedding
))
conn.commit()Стоимость эмбеддингов: text-embedding-3-small стоит ~$0.02 за 1 млн токенов. Каталог в 50 000 книг с описаниями по ~200 токенов — около $0.2 за полную индексацию. Пересчитывать правда придется при изменении контента.
Шаг 4. Семантический поиск
Оператор <=> в pgvector вычисляет косинусное расстояние между векторами. Чем ближе к нулю — тем «ближе» смысл:
def semantic_search(conn, query: str, limit: int = 5, lang: str = None):
"""Найти релевантные записи по смыслу вопроса."""
query_embedding = get_embedding(query)
sql = """
SELECT
document_id, title, content,
1 - (embedding <=> %s::vector) AS similarity,
metadata
FROM catalog_chunks
{lang_filter}
ORDER BY embedding <=> %s::vector
LIMIT %s
"""
lang_filter = "WHERE language = %s" if lang else ""
with conn.cursor() as cur:
params = [query_embedding]
if lang: params.append(lang)
params += [query_embedding, limit]
cur.execute(sql.format(lang_filter=lang_filter), params)
return cur.fetchall()
# Пример: поиск только по казахскоязычным книгам
results = semantic_search(conn,
query="машинное обучение нейронные сети",
lang="kz"
)Шаг 5. RAG — собираем финальный ответ
Найденные записи передаём как контекст в языковую модель. Модель отвечает строго на основе каталога, не выдумывая несуществующие книги:
from anthropic import Anthropic
claude = Anthropic() # ANTHROPIC_API_KEY из env
def rag_answer(conn, user_question: str) -> str:
"""Ответить на вопрос на основе каталога."""
# 1. Находим релевантные книги
results = semantic_search(conn, user_question, limit=5)
# 2. Формируем контекст из найденных записей
context = "\n\n".join([
f"[{r[1]}]\n{r[2][:400]}" # title + начало описания
for r in results
])
# 3. Отправляем в Claude
message = claude.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=1024,
system="""Ты помощник библиотеки. Отвечай только
на основе предоставленного каталога. Если книги нет —
так и скажи, не придумывай.""",
messages=[{
"role": "user",
"content": f"Каталог:\n{context}\n\nВопрос: {user_question}"
}]
)
return message.content[0].textПочему Claude, а не GPT-4? Большое контекстное окно позволяет передать больше найденных записей одновременно. На практике при 5–10 результатах разница минимальна — можно использовать gpt-4o по аналогии, API идентичен.
Производительность: реальные цифры
поиск при 100К записей — 2–5 мс
каждая индексация 50К книг ~$0.2
0 дополнительных сервисов
Узкое место пайплайна — не поиск по pgvector, а вызовы API. text-embedding-3-small отвечает за 100–300 мс, языковая модель — 500 мс–3 сек. Оптимизировать latency поиска с 5 мс до 1 мс нет смысла, пока генерация занимает в 100 раз больше времени.
Бонус: гибридный поиск
Чистый семантический поиск иногда промахивается по точным именам, авторам и ISBN. Для каталога имеет смысл совмещать векторный поиск с полнотекстовым — это называется гибридным поиском:
-- Гибридный поиск: вектор + полнотекстовый (70/30)
SELECT document_id, title,
(1 - (embedding <=> %s)) * 0.7
+ ts_rank(to_tsvector('russian', content),
plainto_tsquery('russian', %s)) * 0.3
AS score
FROM catalog_chunks
WHERE
to_tsvector('russian', content) @@ plainto_tsquery('russian', %s)
OR embedding <=> %s < 0.4
ORDER BY score DESC
LIMIT 10;Почему это будет работать лучше: векторный поиск отлично справляется с синонимами и смысловыми запросами, а полнотекстовый — с точными именами, кодами УДК и аббревиатурами. Объединение двух методов даёт более высокий «отклик».
Когда pgvector не подойдёт
- Десятки миллионов векторов с мультирегиональными требованиями — тогда смотрите в сторону Qdrant или Pinecone
- Команда без опыта в PostgreSQL — в этом случае managed-решение вроде Supabase снизит порог входа
- Нужны очень сложные фильтры по метаданным с одновременным ANN-поиском — специализированные БД здесь выигрывают
Итог
Для проекта масштаба городского портала или корпоративного каталога (десятки–сотни тысяч записей) pgvector — это всё что нужно. PostgreSQL уже в стеке, докер тоже настроен, CREATE EXTENSION vector занимает секунду. Никакого Pinecone, никаких дополнительных счетов. Пайплайн из трёх компонентов — pgvector + OpenAI Embeddings + Claude/GPT — даёт полноценный семантический поиск за один вечер работы.
Можно сказать что набросал на коленке, если у вас есть какие-то советы по оптимизации или может это решение «такое себе» на ваш взгляд, то я буду рад послушать мнение более опытных коллег. Спасибо что дочитали ;)
Когда передо мной встала задача добавить ИИ-поиск по большому книжному каталогу, первый порыв был — взять Pinecone или Qdrant. Потом мы осмотрелись: PostgreSQL уже стоит, Docker уже настроен, pgvector уже есть в экосистеме. Зачем плодить еще одну векторную БД решил я.
Что такое RAG и зачем это нужно
RAG (Retrieval-Augmented Generation) — архитектурный паттерн, при котором языковая модель перед ответом получает релевантный контекст из базы данных. Вместо того чтобы «придумывать» ответ, модель опирается на реальные данные из базы. Для книжного каталога это означает следующее: пользователь пишет «есть ли у вас книги про машинное обучение на казахском?» — и система находит релевантные записи семантически, а не по точному совпадению ключевых слов. Получаем на выходе реальный «умный поиск»: пользователи ищут разными словами одно и то же понятие и такой способ позволяет осуществлять релевантный поиск.
Архитектура пайплайна будет стакой:
Индексация Документы / каталог → OpenAI Embeddings → pgvector (PostgreSQL)
Запрос Вопрос пользователя → Embed запроса → Similarity search → Claude / GPT → ответ
Шаг 1. Включаем pgvector
Если у вас уже есть PostgreSQL, тогда нужно просто добавить pgvector одной строкой в SQL:
-- Включаем расширение в нужной базе данных
CREATE EXTENSION IF NOT EXISTS vector;
-- Проверяем версию
SELECT extname, extversion FROM pg_extension
WHERE extname = 'vector';
-- extname | extversion
-- vector | 0.8.2Для докера есть готовый образ с уже встроенным pgvector:
# docker-compose.yml
services:
db:
image: pgvector/pgvector:pg16
environment:
POSTGRES_DB: library_rag
POSTGRES_USER: app
POSTGRES_PASSWORD: secret
volumes:
- pgdata:/var/lib/postgresql/dataДля standalone версии PostgreSQL на Ubuntu/Debian ставим: sudo apt install postgresql-16-pgvector.
Расширение живёт рядом с остальными данными и не требует пересборки или миграции существующих таблиц.
Шаг 2. Схема таблицы
Создаём таблицу для записей каталога. Колонка embedding хранит вектор размерностью 1536 — это стандарт модели text-embedding-3-small от OpenAI:
CREATE TABLE catalog_chunks (
id BIGSERIAL PRIMARY KEY,
document_id TEXT NOT NULL, -- ISBN или внутренний ID
title TEXT,
content TEXT NOT NULL, -- текстовый чанк
language TEXT DEFAULT 'ru',
metadata JSONB, -- автор, год, УДК и т.д.
embedding vector(1536), -- OpenAI text-embedding-3-small
created_at TIMESTAMP DEFAULT NOW()
);
-- HNSW-индекс — стандарт де-факто в 2026 году
-- Лучше IVFFlat: можно создать до загрузки данных,
-- выше recall, ниже latency при поиске
CREATE INDEX catalog_embedding_hnsw_idx
ON catalog_chunks
USING hnsw (embedding vector_cosine_ops)
WITH (m = 16, ef_construction = 64);Шаг 3. Индексация — загружаем каталог
Python-скрипт берёт записи из каталога, отправляет текст в OpenAI Embeddings API и сохраняет векторы в PostgreSQL:
import psycopg2
from openai import OpenAI
import hashlib
client = OpenAI() # читает OPENAI_API_KEY из env
def get_embedding(text: str) -> list[float]:
"""Получить вектор для текста через OpenAI API."""
response = client.embeddings.create(
model="text-embedding-3-small", # 1536 dim, $0.02/1M токенов
input=text.replace("\n", " ")
)
return response.data[0].embedding
def index_book(conn, book: dict):
"""Индексировать одну книгу из каталога."""
text = f"{book['title']} {book['author']} {book['description']}"
with conn.cursor() as cur:
# Пропускаем если запись уже есть
cur.execute(
"SELECT id FROM catalog_chunks WHERE document_id=%s",
(book['isbn'],)
)
if cur.fetchone():
return
embedding = get_embedding(text)
cur.execute("""
INSERT INTO catalog_chunks
(document_id, title, content, language, metadata, embedding)
VALUES (%s, %s, %s, %s, %s, %s)
""", (
book['isbn'], book['title'], text,
book.get('lang', 'ru'),
psycopg2.extras.Json({'author': book['author'], 'year': book['year']}),
embedding
))
conn.commit()Стоимость эмбеддингов: text-embedding-3-small стоит ~$0.02 за 1 млн токенов. Каталог в 50 000 книг с описаниями по ~200 токенов — около $0.2 за полную индексацию. Пересчитывать правда придется при изменении контента.
Шаг 4. Семантический поиск
Оператор <=> в pgvector вычисляет косинусное расстояние между векторами. Чем ближе к нулю — тем «ближе» смысл:
def semantic_search(conn, query: str, limit: int = 5, lang: str = None):
"""Найти релевантные записи по смыслу вопроса."""
query_embedding = get_embedding(query)
sql = """
SELECT
document_id, title, content,
1 - (embedding <=> %s::vector) AS similarity,
metadata
FROM catalog_chunks
{lang_filter}
ORDER BY embedding <=> %s::vector
LIMIT %s
"""
lang_filter = "WHERE language = %s" if lang else ""
with conn.cursor() as cur:
params = [query_embedding]
if lang: params.append(lang)
params += [query_embedding, limit]
cur.execute(sql.format(lang_filter=lang_filter), params)
return cur.fetchall()
# Пример: поиск только по казахскоязычным книгам
results = semantic_search(conn,
query="машинное обучение нейронные сети",
lang="kz"
)Шаг 5. RAG — собираем финальный ответ
Найденные записи передаём как контекст в языковую модель. Модель отвечает строго на основе каталога, не выдумывая несуществующие книги:
from anthropic import Anthropic
claude = Anthropic() # ANTHROPIC_API_KEY из env
def rag_answer(conn, user_question: str) -> str:
"""Ответить на вопрос на основе каталога."""
# 1. Находим релевантные книги
results = semantic_search(conn, user_question, limit=5)
# 2. Формируем контекст из найденных записей
context = "\n\n".join([
f"[{r[1]}]\n{r[2][:400]}" # title + начало описания
for r in results
])
# 3. Отправляем в Claude
message = claude.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=1024,
system="""Ты помощник библиотеки. Отвечай только
на основе предоставленного каталога. Если книги нет —
так и скажи, не придумывай.""",
messages=[{
"role": "user",
"content": f"Каталог:\n{context}\n\nВопрос: {user_question}"
}]
)
return message.content[0].textПочему Claude, а не GPT-4? Большое контекстное окно позволяет передать больше найденных записей одновременно. На практике при 5–10 результатах разница минимальна — можно использовать gpt-4o по аналогии, API идентичен.
Производительность: реальные цифры
поиск при 100К записей — 2–5 мс
каждая индексация 50К книг ~$0.2
0 дополнительных сервисов
Узкое место пайплайна — не поиск по pgvector, а вызовы API. text-embedding-3-small отвечает за 100–300 мс, языковая модель — 500 мс–3 сек. Оптимизировать latency поиска с 5 мс до 1 мс нет смысла, пока генерация занимает в 100 раз больше времени.
Бонус: гибридный поиск
Чистый семантический поиск иногда промахивается по точным именам, авторам и ISBN. Для каталога имеет смысл совмещать векторный поиск с полнотекстовым — это называется гибридным поиском:
-- Гибридный поиск: вектор + полнотекстовый (70/30)
SELECT document_id, title,
(1 - (embedding <=> %s)) * 0.7
+ ts_rank(to_tsvector('russian', content),
plainto_tsquery('russian', %s)) * 0.3
AS score
FROM catalog_chunks
WHERE
to_tsvector('russian', content) @@ plainto_tsquery('russian', %s)
OR embedding <=> %s < 0.4
ORDER BY score DESC
LIMIT 10;Почему это будет работать лучше: векторный поиск отлично справляется с синонимами и смысловыми запросами, а полнотекстовый — с точными именами, кодами УДК и аббревиатурами. Объединение двух методов даёт более высокий «отклик».
Когда pgvector не подойдёт
- Десятки миллионов векторов с мультирегиональными требованиями — тогда смотрите в сторону Qdrant или Pinecone
- Команда без опыта в PostgreSQL — в этом случае managed-решение вроде Supabase снизит порог входа
- Нужны очень сложные фильтры по метаданным с одновременным ANN-поиском — специализированные БД здесь выигрывают
Итог
Для проекта масштаба городского портала или корпоративного каталога (десятки–сотни тысяч записей) pgvector — это всё что нужно. PostgreSQL уже в стеке, докер тоже настроен, CREATE EXTENSION vector занимает секунду. Никакого Pinecone, никаких дополнительных счетов. Пайплайн из трёх компонентов — pgvector + OpenAI Embeddings + Claude/GPT — даёт полноценный семантический поиск за один вечер работы.
Можно сказать что набросал на коленке, если у вас есть какие-то советы по оптимизации или может это решение «такое себе» на ваш взгляд, то я буду рад послушать мнение более опытных коллег. Спасибо что дочитали ;)

 Поделиться
Поделиться




