The post has been translated automatically. Original language: Russian



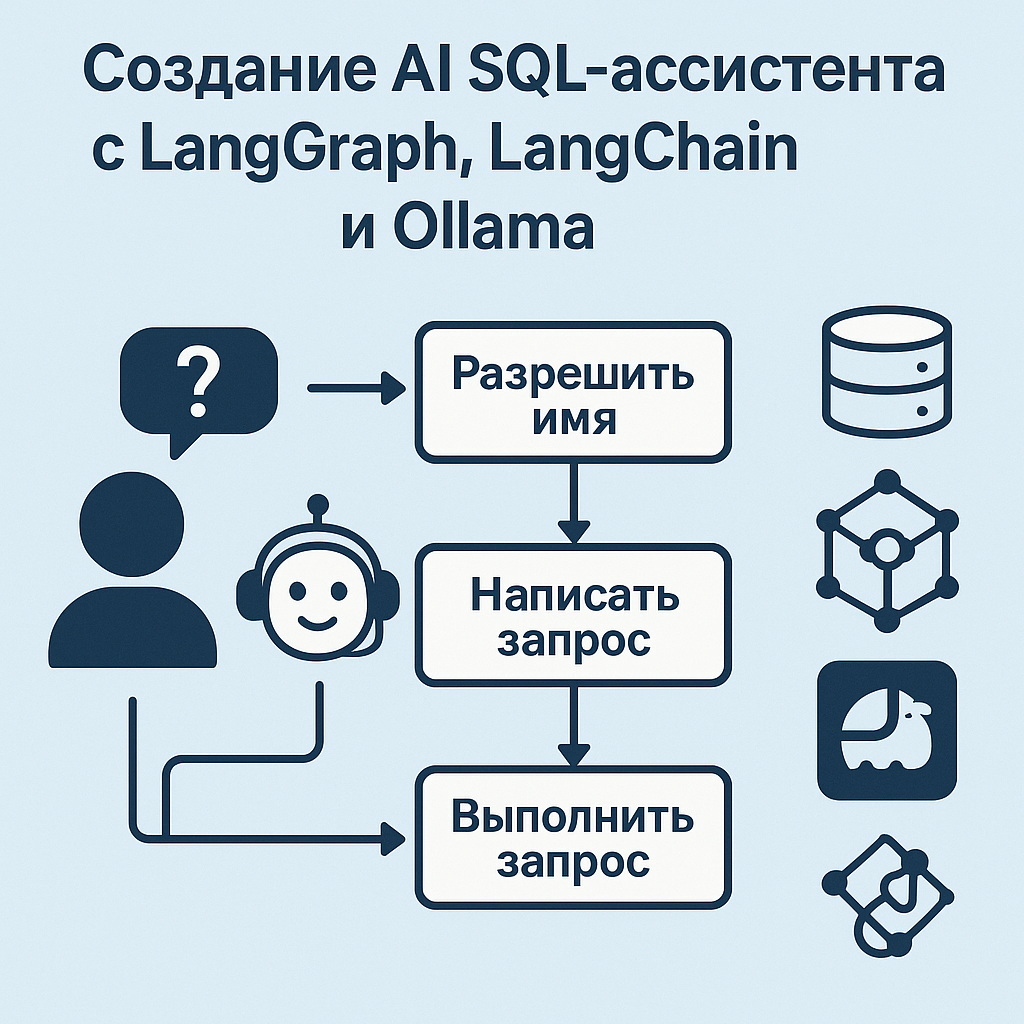
In this article, we'll look at how to write a simple but completely offline voice assistant in Python. He can:
- Listen to the user's speech through the microphone.
- Recognize voice (speech-to-text) using Faster Whisper— a local Whisper model that does not require an internet connection.
- Analyze the question and generate an answer using Ollama, a locally launched LLM (large language model) running without a server in the cloud.
- To voice the response text (text-to-speech) via the pyttsx3 library.
The main advantage of such an assistant is that it works without the Internet, and your personal data (voice sound, transcribed text, dialogue history) is not transmitted to any external services.
First, make sure that you have the following packages installed:
- PyAudio – for recording audio from a microphone.
- wave – to save recorded audio to a WAV file (standard Python library).
- Faster Whisper is a local library for speech recognition using the Whisper model.
- Ollama is a locally installed LLM that does not require an internet connection.
- pyttsx3 is a speech synthesis library (TTS) that also works offline.
pip install pyaudio faster-whisper ollama pyttsx3The main stages of the assistant's work:
- Initialization:Importing libraries, Launching PyAudio and configuring recording parameters, Downloading the local Whisper model (Faster Whisper), Initializing the voice acting engine (pyttsx3), Checking the availability of Ollama (make sure that it is running locally and does not require network access).
- Importing libraries,
- Launching PyAudio and configuring recording settings,
- Loading the local Whisper model (Faster Whisper),
- Initialization of the voice acting engine (pyttsx3),
- Check the availability of Ollama (make sure that it is running locally and does not require network access).
- Recording a voice command:The code opens the PyAudio recording stream and "listens" to the microphone.Detects when the user has stopped speaking by the volume level (RMS).After a few seconds of silence, it automatically stops recording and saves it to a WAV file.
- The code opens the PyAudio recording stream and "listens" to the microphone.
- Detects when the user has stopped speaking by the volume level (RMS).
- After a few seconds of silence, it automatically stops recording and saves it to a WAV file.
- Speech recognition (speech-to-text):The WAV file is transferred to the Faster Whisper (local model).The model returns the decrypted text without sending any data to the cloud.
- The WAV file is transferred to the Faster Whisper (local model).
- The model returns the decrypted text without sending any data to the cloud.
- Generating a response:The decrypted text (the user's question) is added to the dialog history.The whole story is sent to Ollama, which runs locally without internet.Ollama generates a response using a loaded large language model.
- The decrypted text (the user's question) is added to the dialog history.
- The whole story is sent to Ollama, which runs locally without internet.
- Ollama generates a response using a loaded large language model.
- Voicing the response (text-to-speech):The assistant voices the answer through pyttsx3.Everything happens offline and does not depend on online services.
- The assistant voices the answer through pyttsx3.
- Everything happens offline and does not depend on online services.
Below is an example of the code that implements the described functions.
import pyaudio
import wave
import time
import sys
import struct
import math
from faster_whisper import WhisperModel
import ollama
import pyttsx3
import threading
engine = pyttsx3.init()
model_size = "large-v3"
model = WhisperModel(model_size, device="cpu", compute_type="int8")
CHUNK = 1024 # Number of samples in one frame
RATE = 16000 # Sampling rate
FORMAT = pyaudio.paInt16
CHANNELS = 1
# The volume threshold below which we consider that the user is "silent"
THRESHOLD = 300
# How many consecutive seconds should I be "silent" to stop recording
SILENCE_LIMIT = 2.0
# We store the entire history of the dialog here
messages = []
def rms(data):
"""
Calculate the approximate volume (RMS) for one byte block.
data: byte string read from PyAudio
"""
count = len(data) // 2 # Number of samples in int16 format
format_str = "<" + "h" * count
shorts = struct.unpack_from(format_str, data)
sum_squares = 0.0
for sample in shorts:
sum_squares += sample * sample
if count == 0:
return 0
return math.sqrt(sum_squares / count)
def record_once(filename="audio.wav"):
"""
We record one fragment of speech (until 'silence') and save it to a WAV file.
We return the path to the recorded file.
"""
p = pyaudio.PyAudio()
stream = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=CHUNK)
frames = []
print("Start of recording (speak)...")
silence_counter = 0 # Counter of "silent" chunks
while True:
data = stream.read(CHUNK)
frames.append(data)
# Calculate the volume of the current CHUNK
current_rms = rms(data)
if current_rms < THRESHOLD:
# Volume below threshold => "silence"
silence_counter += 1
else:
silence_counter = 0
# If the total length of silent blocks has exceeded SILENCE_LIMIT seconds, exit
if silence_counter * (CHUNK / RATE) > SILENCE_LIMIT:
break
print("Recording completed.")
stream.stop_stream()
stream.close()
p.terminate()
# Save it to a WAV file
wf = wave.open(filename, 'wb')
wf.setnchannels(CHANNELS)
wf.setsampwidth(p.get_sample_size(FORMAT))
wf.setframerate(RATE)
wf.writeframes(b''.join(frames))
wf.close()
return filename
def transcribe(filename):
"""
We recognize the file using faster_whisper.
Returning the recognized text.
"""
segments, info = model.transcribe(filename, beam_size=8)
print("Detected language '%s' with probability %f" % (info.language, info.language_probability))
texts = ''
for segment in segments:
texts += segment.text
return texts
def main():
while True:
#1. Recording a fragment of speech
audio_path = record_once("audio.wav")
# 2. Recognize
user_text = transcribe(audio_path)
# If recognition suddenly returns an empty string, skip it
if not user_text.strip():
print("The user did not say anything or was not recognized, we continue to listen...")
continue
print("The user said:", user_text)
#3. Add to the history as a new message from the user
messages.append({"role": "user", "content": user_text})
#4. Sending the WHOLE story to Ollama
# ollama.chat allows you to send a list of messages
response = ollama.chat(
'qwen2.5-coder:latest',
messages=messages,
)
# 5. Extracting the response text
assistant_text = response['message']['content']
print("Assistant replied:", assistant_text)
# 6. Save the assistant's response to the history
messages.append({"role": "assistant", "content": assistant_text})
# 7. Voicing the response
engine.say(assistant_text)
engine.runAndWait()
# Then the cycle repeats, we record again, etc.
if __name__ == "__main__":
main()
- Faster Whisper is the local version of Whisper. All audio processing for speech recognition takes place inside your computer.
- Ollama — this tool can work completely without an internet connection if you download the required language model in advance. The response is generated locally.
- pyttsx3 is a text-to-speech library that does not use external APIs. Everything is synthesized on your computer.
- PyAudio — reads audio from the microphone locally and does not forward it to the network.
Thus, no stage of the assistant's work sends your data to the Internet. You control which models and versions of Whisper (or other LLMs) you use.
- Model selection: Try different Faster Whisper models (small, medium, large) to find a balance between speed and recognition accuracy.
- Noise reduction: If you have a noisy environment, you can add a library for noise reduction and improve the recognition quality.
- Alternative language models: Ollama supports not only qwen2.5-coder, but also other models. Choose the one that is best suited for your tasks (for example, for code generation, general chat, translations, etc.).
- Graphical interface: Add a simple GUI (for example, on PyQt or tkinter) to control the assistant and see the recognized text and responses.
We have created an offline voice assistant that works completely without the Internet - from recording a microphone and speech recognition to generating and voicing a response. This is a great way to ensure the safety of personal data and flexibly customize the system for yourself. Now you can expand the assistant's functionality by teaching it to execute different commands and process complex dialogues — all this locally and with full control over the data.
Experiment, add new features, and let your local assistant become an indispensable tool in your work and daily life!
В этой статье мы рассмотрим, как написать простого, но полностью офлайн-голосового ассистента на Python. Он умеет:
- Слушать речь пользователя через микрофон.
- Распознавать голос (speech-to-text), используя Faster Whisper — локальную модель Whisper, не требующую подключения к интернету.
- Анализировать вопрос и формировать ответ с помощью Ollama — локально запущенной LLM (large language model), работающей без сервера в облаке.
- Озвучивать текст ответа (text-to-speech) через библиотеку pyttsx3.
Главное преимущество такого ассистента — он работает без интернета, и ваши личные данные (звук голоса, расшифрованный текст, история диалога) не передаются в какие-либо внешние сервисы.
Сначала убедитесь, что у вас установлены следующие пакеты:
- PyAudio – для записи аудио с микрофона.
- wave – для сохранения записанного звука в WAV-файл (стандартная библиотека Python).
- Faster Whisper – локальная библиотека для распознавания речи с помощью модели Whisper.
- Ollama – локально установленная LLM, не требующая подключения к интернету.
- pyttsx3 – библиотека синтеза речи (TTS), которая тоже работает офлайн.
pip install pyaudio faster-whisper ollama pyttsx3Основные этапы работы ассистента:
- Инициализация:Импорт библиотек,Запуск PyAudio и настройка параметров записи,Загрузка локальной модели Whisper (Faster Whisper),Инициализация движка озвучки (pyttsx3),Проверка доступности Ollama (убедитесь, что она запущена локально и не требует доступа в сеть).
- Импорт библиотек,
- Запуск PyAudio и настройка параметров записи,
- Загрузка локальной модели Whisper (Faster Whisper),
- Инициализация движка озвучки (pyttsx3),
- Проверка доступности Ollama (убедитесь, что она запущена локально и не требует доступа в сеть).
- Запись голосовой команды:Код открывает поток записи PyAudio и «слушает» микрофон.Определяет, когда пользователь перестал говорить, по уровню громкости (RMS).После нескольких секунд тишины автоматически останавливает запись и сохраняет ее в WAV-файл.
- Код открывает поток записи PyAudio и «слушает» микрофон.
- Определяет, когда пользователь перестал говорить, по уровню громкости (RMS).
- После нескольких секунд тишины автоматически останавливает запись и сохраняет ее в WAV-файл.
- Распознавание речи (speech-to-text):WAV-файл передается в Faster Whisper (локальная модель).Модель возвращает расшифрованный текст без отправки каких-либо данных в облако.
- WAV-файл передается в Faster Whisper (локальная модель).
- Модель возвращает расшифрованный текст без отправки каких-либо данных в облако.
- Генерация ответа:Расшифрованный текст (вопрос пользователя) добавляется в историю диалога.Вся история отправляется в Ollama, которая работает локально без интернета.Ollama формирует ответ, используя загруженную большую языковую модель.
- Расшифрованный текст (вопрос пользователя) добавляется в историю диалога.
- Вся история отправляется в Ollama, которая работает локально без интернета.
- Ollama формирует ответ, используя загруженную большую языковую модель.
- Озвучивание ответа (text-to-speech):Ассистент озвучивает ответ через pyttsx3.Все происходит офлайн и не зависит от онлайн-сервисов.
- Ассистент озвучивает ответ через pyttsx3.
- Все происходит офлайн и не зависит от онлайн-сервисов.
Ниже приведен пример кода, в котором реализованы описанные функции.
import pyaudio
import wave
import time
import sys
import struct
import math
from faster_whisper import WhisperModel
import ollama
import pyttsx3
import threading
engine = pyttsx3.init()
model_size = "large-v3"
model = WhisperModel(model_size, device="cpu", compute_type="int8")
CHUNK = 1024 # Количество сэмплов в одном фрейме
RATE = 16000 # Частота дискретизации
FORMAT = pyaudio.paInt16
CHANNELS = 1
# Порог громкости, ниже которого считаем, что пользователь «молчит»
THRESHOLD = 300
# Сколько секунд подряд нужно «молчать», чтобы остановить запись
SILENCE_LIMIT = 2.0
# Здесь храним всю историю диалога
messages = []
def rms(data):
"""
Вычисляем примерную громкость (RMS) для одного блока байт.
data: байтовая строка, считанная из PyAudio
"""
count = len(data) // 2 # Количество отсчетов при формате int16
format_str = "<" + "h" * count
shorts = struct.unpack_from(format_str, data)
sum_squares = 0.0
for sample in shorts:
sum_squares += sample * sample
if count == 0:
return 0
return math.sqrt(sum_squares / count)
def record_once(filename="audio.wav"):
"""
Записываем один фрагмент речи (до 'тишины') и сохраняем в WAV-файл.
Возвращаем путь к записанному файлу.
"""
p = pyaudio.PyAudio()
stream = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=CHUNK)
frames = []
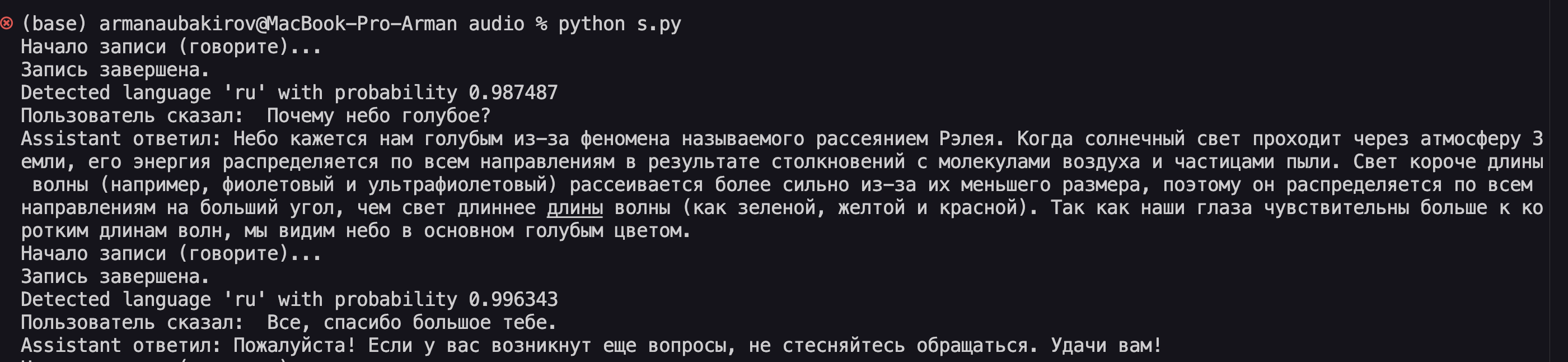
print("Начало записи (говорите)...")
silence_counter = 0 # Счётчик «тихих» CHUNK’ов
while True:
data = stream.read(CHUNK)
frames.append(data)
# Посчитаем громкость текущего CHUNK
current_rms = rms(data)
if current_rms < THRESHOLD:
# Громкость ниже порога => «тишина»
silence_counter += 1
else:
silence_counter = 0
# Если суммарная длина тихих блоков превысила SILENCE_LIMIT секунд, выходим
if silence_counter * (CHUNK / RATE) > SILENCE_LIMIT:
break
print("Запись завершена.")
stream.stop_stream()
stream.close()
p.terminate()
# Сохраняем в WAV-файл
wf = wave.open(filename, 'wb')
wf.setnchannels(CHANNELS)
wf.setsampwidth(p.get_sample_size(FORMAT))
wf.setframerate(RATE)
wf.writeframes(b''.join(frames))
wf.close()
return filename
def transcribe(filename):
"""
Распознаём файл с помощью faster_whisper.
Возвращаем распознанный текст.
"""
segments, info = model.transcribe(filename, beam_size=8)
print("Detected language '%s' with probability %f" % (info.language, info.language_probability))
texts = ''
for segment in segments:
texts += segment.text
return texts
def main():
while True:
# 1. Запись фрагмента речи
audio_path = record_once("audio.wav")
# 2. Распознаём
user_text = transcribe(audio_path)
# Если вдруг распознавание вернуло пустую строку — пропускаем
if not user_text.strip():
print("Пользователь ничего не сказал или не распознано, продолжаем слушать...")
continue
print("Пользователь сказал:", user_text)
# 3. Добавляем в историю как новое сообщение от пользователя
messages.append({"role": "user", "content": user_text})
# 4. Отправляем ВСЮ историю в Ollama
# ollama.chat позволяет передавать список сообщений
response = ollama.chat(
'qwen2.5-coder:latest',
messages=messages,
)
# 5. Извлекаем текст ответа
assistant_text = response['message']['content']
print("Assistant ответил:", assistant_text)
# 6. Сохраняем ответ ассистента в историю
messages.append({"role": "assistant", "content": assistant_text})
# 7. Озвучиваем ответ
engine.say(assistant_text)
engine.runAndWait()
# Далее цикл повторяется, снова записываем и т.д.
if __name__ == "__main__":
main()
- Faster Whisper — локальная версия Whisper. Вся обработка звука для распознавания речи идет внутри вашего компьютера.
- Ollama — этот инструмент может работать полностью без подключения к интернету, если вы заранее скачаете нужную языковую модель. Генерация ответа происходит локально.
- pyttsx3 — библиотека текст-в-речь, которая не использует внешние API. Все синтезируется на вашем компьютере.
- PyAudio — читает звук с микрофона локально и не пересылает его в сеть.
Таким образом, никакой этап работы ассистента не отправляет ваши данные в интернет. Вы сами контролируете, какие модели и версии Whisper (или других LLM) вы используете.
- Выбор модели: Попробуйте разные модели Faster Whisper (small, medium, large), чтобы найти баланс между скоростью и точностью распознавания.
- Шумоподавление: Если у вас шумная среда, можно добавить библиотеку для шумоподавления и улучшить качество распознавания.
- Альтернативные языковые модели: Ollama поддерживает не только qwen2.5-coder, но и другие модели. Выберите ту, которая лучше подходит для ваших задач (например, для генерации кода, общего чата, переводов и т. д.).
- Графический интерфейс: Добавьте простой GUI (например, на PyQt или tkinter), чтобы управлять ассистентом и видеть распознанный текст и ответы.
Мы создали офлайн-голосового ассистента, который полностью работает без интернета — от записи микрофона и распознавания речи до генерации и озвучивания ответа. Это отличный способ обеспечить сохранность личных данных и гибко настраивать систему под себя. Теперь вы можете расширять функциональность ассистента, обучая его выполнять разные команды и обрабатывать сложные диалоги — все это локально и с полным контролем над данными.
Экспериментируйте, добавляйте новые функции, и пусть ваш локальный ассистент станет незаменимым инструментом в работе и повседневной жизни!
 Share
Share