The post has been translated automatically. Original language: Russian



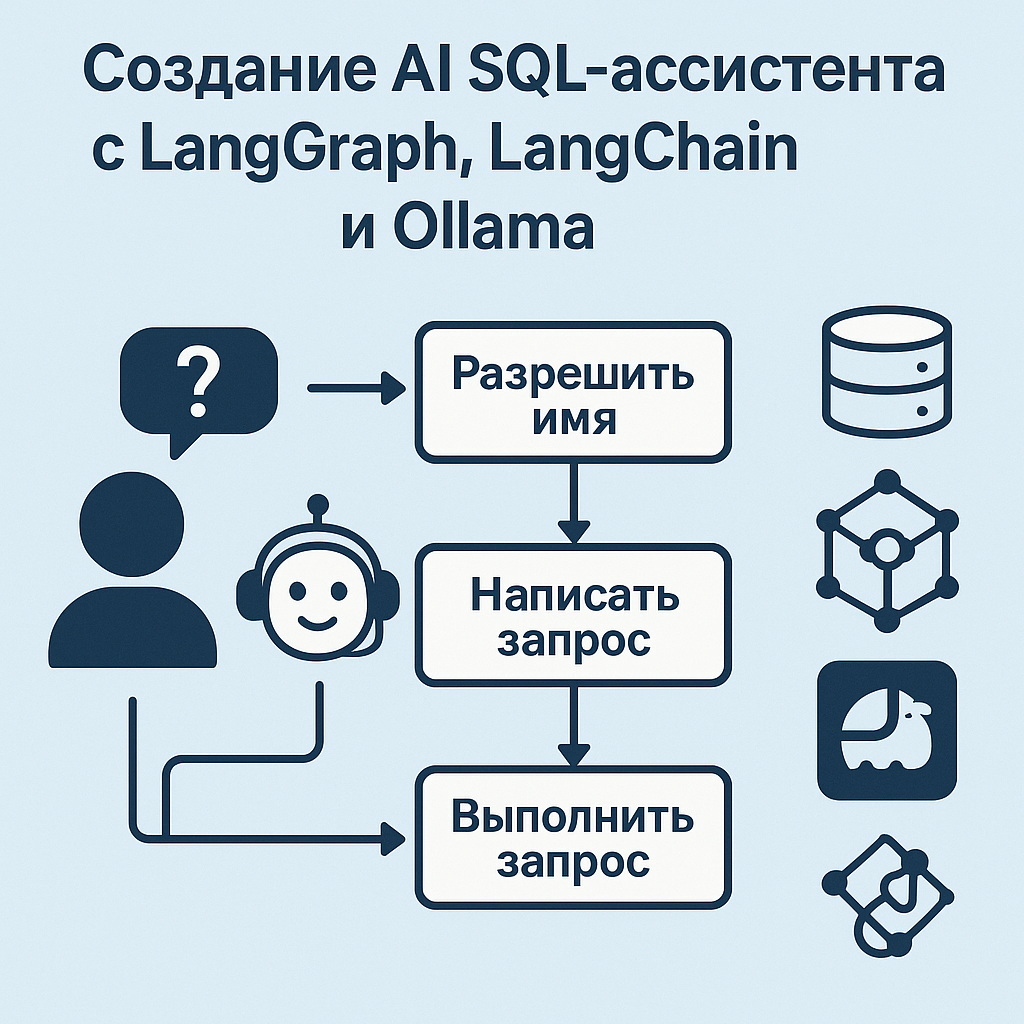
In today's data world, users increasingly need to work with databases quickly and intuitively. However, not everyone knows SQL. That's why we created an AI assistant that:
- accepts questions in natural language,
- interprets them,
- writes correct SQL queries,
- fulfills them,
- and forms an understandable response.
This solution is based on LangChain, LangGraph and Ollama, and works with PostgreSQL or ClickHouse.
- LLM: Qwen 3 (via Ollama, locally).
- LangChain: SQL generation, query execution.
- LangGraph: managing the processing steps.
- PostgreSQL: data source.
- Python: glue code and logic.
pip install langchain langgraph langchain-community langchain-ollama sqlalchemyfrom langchain_community.utilities import SQLDatabase
from langchain_ollama import ChatOllama
import re
from typing_extensions import TypedDict, Annotated
from langchain_core.prompts import ChatPromptTemplate
from langchain_community.tools.sql_database.tool import QuerySQLDatabaseTool
from langgraph.graph import START, StateGraph
import difflib
from sqlalchemy import text
from typing import Optional, List, Connecting to the database
db = SQLDatabase.from_uri( # Be sure to store the URI in the .env file!
"postgresql://<username>:<password>@<host>:<port>/<dbname>",
include_tables=["projects"],
), Connecting to LLM (via Ollama)
llm = ChatOllama(
model="qwen3:32b",
base_url="http://<ollama-host>:11434",
num_ctx=8192,
temperature=0.1,
)Pythoncopyedactclass State(TypedDict):
question: str
query: str
result: str
answer: str
columns_to_search: Optional[List[str]]
KNOWN_NAMES: set[str] = set()
with db._engine.begin() as conn:
for col in ("primary_executive", "product_managers", "collaborators"):
result = conn.execute(text(f"SELECT DISTINCT {col} FROM projects WHERE {col} IS NOT NULL"))
for row in result:
if row[0]:
names = str(row[0]).strip().split(', ')
KNOWN_NAMES.update(name.strip() for name in names if name)
system_template = """
Given an input question, create a syntactically correct {dialect} query to run to help find the answer. \
Unless the user specifies a specific number of examples they wish to obtain, always limit your query to at most {top_k} results.
When searching for names, use the following columns: {columns_to_search}. \
Apply LIKE '%name fragment%' separately for each column, and combine multiple conditions using OR.
Never query for all the columns from a table, only select the few relevant columns needed for answering the question.
Pay attention to use only the column names you see in the schema description.
When searching by department or division (stored in the 'direction' column), use LIKE '%fragment%'. \
Interpret common abbreviations .
Only use the following tables:
{table_info}
"""
human_template = "Question: {input}"
custom_query_prompt = ChatPromptTemplate.from_messages([
("system", system_template),
("human", human_template),
])def resolve_name(state: State):
question = state["question"]
tokens = re.findall(r"[A-Za-zА-Yaa-Eee]{4,}", question)
corrected = {}
for tok in tokens:
if any(tok.lower() == name.lower() for name in KNOWN_NAMES):
continue
match = difflib.get_close_matches(tok, KNOWN_NAMES, n=1, cutoff=0.75)
if match:
corrected[tok] = match[0]
if corrected:
new_q = question
for wrong, right in corrected.items():
new_q = re.sub(rf"{wrong}", right, new_q, flags=re.IGNORECASE)
return {"question": new_q}
return {"question": question}
def analyze_question_for_role(state: State) -> dict:
question = state["question"].lower()
participation_words = [
"involved", "performers", "managers", "work", "appears", "employees"
]
tokens = re.findall(r"[A-Za-zА-Yaa-Eee]{4,}", question)
name_matches = [tok for tok in tokens if any(tok.lower() in name.lower() for name in KNOWN_NAMES)]
if not name_matches:
return state
multiple_names = len(name_matches) > 1
has_keywords = any(word in question for word in participation_words)
columns = ["primary_executive", "product_managers", "collaborators"] if (multiple_names or has_keywords) else ["primary_executive", "product_managers"]
return {**state, "columns_to_search": columns}
class QueryOutput(TypedDict):
query: Annotated[str, ..., "Syntactically valid SQL query."]
def write_query(state: State):
prompt_args = {
"dialect": db.dialect,
"top_k": 10,
"table_info": db.get_table_info(),
"columns_to_search": ", ".join(state.get("columns_to_search", [])) if "columns_to_search" in state else "",
"input": state["question"],
}
prompt = custom_query_prompt.invoke(prompt_args)
result = llm.with_structured_output(QueryOutput).invoke(prompt)
print("write_query")
return {"query": result["query"]}
def execute_query(state: State):
print("execute_query")
return {"result": QuerySQLDatabaseTool(db=db).invoke(state["query"])}
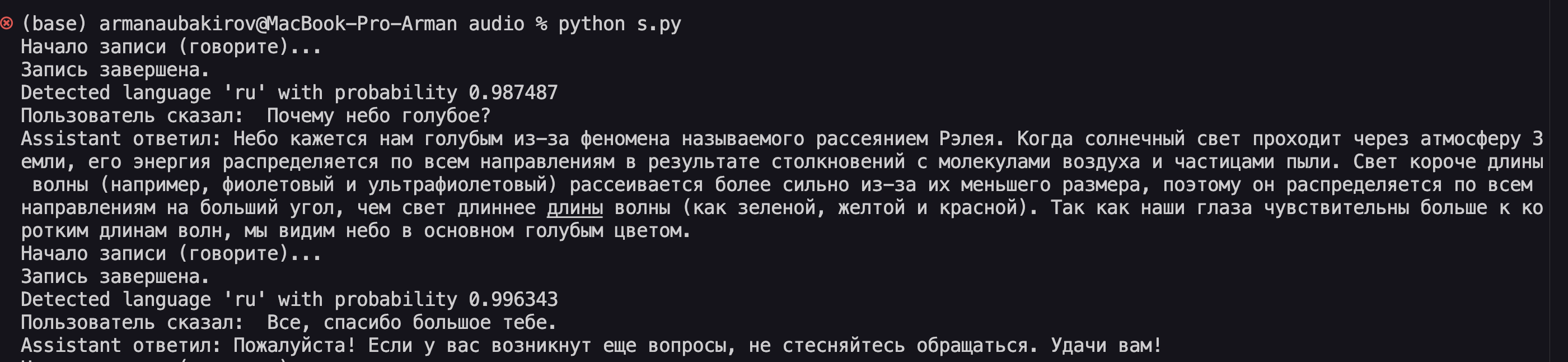
async def generate_answer(state: State):
prompt = (
"Given the following user question, executed SQL query, and SQL result, "
"answer the user's question based only on the SQL result.\n\n"
"You must answer in Russian language.\n\n"
f"User Question:\n{state['question']}\n\n"
f"Executed SQL Query:\n{state['query']}\n\n"
f"SQL Result:\n{state['result']}\n\n"
"Now write a complete and understandable answer in Russian."
)
print("generate_answer")
response = await llm.ainvoke(prompt)
return {"answer": response.content}
graph_builder = StateGraph(State)
graph_builder.add_node("resolve_name", resolve_name)
graph_builder.add_node("analyze_question_for_role", analyze_question_for_role)
graph_builder.add_node("write_query", write_query)
graph_builder.add_node("execute_query", execute_query)
graph_builder.add_node("generate_answer", generate_answer)
graph_builder.add_edge(START, "resolve_name")
graph_builder.add_edge("resolve_name", "analyze_question_for_role")
graph_builder.add_edge("analyze_question_for_role", "write_query")
graph_builder.add_edge("write_query", "execute_query")
graph_builder.add_edge("execute_query", "generate_answer")
graph = graph_builder.compile()
import asyncio
async def ask_stream(question: str):
async for event in graph.astream_events({"question": question}, version="v2"):
kind = event["event"]
if kind == "on_chat_model_stream":
print(event["data"]["chunk"].content, end="", flush=True)
elif kind == "on_tool_end":
output = event["data"].get("output")
if output:
print(f"\n[Tool Output]: {output}\n")
print("\n\n✅ The response is complete.")
Using LangChain and LangGraph, you can:
- quickly develop custom LLM assistants,
- automate SQL access to data,
- use private LLMs without transferring data to the cloud.
This system is the basis for the implementation of a smart chatbot in the corporate BI ecosystem.
В современном мире данных пользователи всё чаще нуждаются в быстрой и интуитивной работе с базами данных. Однако далеко не каждый владеет SQL. Поэтому мы создали AI-помощника, который:
- принимает вопросы на естественном языке,
- интерпретирует их,
- пишет корректные SQL-запросы,
- исполняет их,
- и формирует понятный ответ.
💡 Это решение построено на LangChain, LangGraph и Ollama, и работает с PostgreSQL или ClickHouse.
- LLM: Qwen 3 (через Ollama, локально).
- LangChain: генерация SQL, выполнение запросов.
- LangGraph: управление шагами обработки.
- PostgreSQL: источник данных.
- Python: glue-код и логика.
pip install langchain langgraph langchain-community langchain-ollama sqlalchemyfrom langchain_community.utilities import SQLDatabase
from langchain_ollama import ChatOllama
import re
from typing_extensions import TypedDict, Annotated
from langchain_core.prompts import ChatPromptTemplate
from langchain_community.tools.sql_database.tool import QuerySQLDatabaseTool
from langgraph.graph import START, StateGraph
import difflib
from sqlalchemy import text
from typing import Optional, List🔐 Подключение к базе данных
db = SQLDatabase.from_uri( # Обязательно храните URI в .env файле!
"postgresql://<username>:<password>@<host>:<port>/<dbname>",
include_tables=["projects"],
)🧠 Подключение к LLM (через Ollama)
llm = ChatOllama(
model="qwen3:32b",
base_url="http://<ollama-host>:11434",
num_ctx=8192,
temperature=0.1,
)pythonКопироватьРедактироватьclass State(TypedDict):
question: str
query: str
result: str
answer: str
columns_to_search: Optional[List[str]]
KNOWN_NAMES: set[str] = set()
with db._engine.begin() as conn:
for col in ("primary_executive", "product_managers", "collaborators"):
result = conn.execute(text(f"SELECT DISTINCT {col} FROM projects WHERE {col} IS NOT NULL"))
for row in result:
if row[0]:
names = str(row[0]).strip().split(', ')
KNOWN_NAMES.update(name.strip() for name in names if name)
system_template = """
Given an input question, create a syntactically correct {dialect} query to run to help find the answer. \
Unless the user specifies a specific number of examples they wish to obtain, always limit your query to at most {top_k} results.
When searching for names, use the following columns: {columns_to_search}. \
Apply LIKE '%name fragment%' separately for each column, and combine multiple conditions using OR.
Never query for all the columns from a table, only select the few relevant columns needed for answering the question.
Pay attention to use only the column names you see in the schema description.
When searching by department or division (stored in the 'direction' column), use LIKE '%fragment%'. \
Interpret common abbreviations .
Only use the following tables:
{table_info}
"""
human_template = "Question: {input}"
custom_query_prompt = ChatPromptTemplate.from_messages([
("system", system_template),
("human", human_template),
])def resolve_name(state: State):
question = state["question"]
tokens = re.findall(r"[A-Za-zА-Яа-яЁёІҚҢӨҮҰӘіқңөүұә]{4,}", question)
corrected = {}
for tok in tokens:
if any(tok.lower() == name.lower() for name in KNOWN_NAMES):
continue
match = difflib.get_close_matches(tok, KNOWN_NAMES, n=1, cutoff=0.75)
if match:
corrected[tok] = match[0]
if corrected:
new_q = question
for wrong, right in corrected.items():
new_q = re.sub(rf"{wrong}", right, new_q, flags=re.IGNORECASE)
return {"question": new_q}
return {"question": question}
def analyze_question_for_role(state: State) -> dict:
question = state["question"].lower()
participation_words = [
"участвует", "исполнители", "менеджеров", "работал", "фигурирует", "сотрудников"
]
tokens = re.findall(r"[A-Za-zА-Яа-яЁёІҚҢӨҮҰӘіқңөүұә]{4,}", question)
name_matches = [tok for tok in tokens if any(tok.lower() in name.lower() for name in KNOWN_NAMES)]
if not name_matches:
return state
multiple_names = len(name_matches) > 1
has_keywords = any(word in question for word in participation_words)
columns = ["primary_executive", "product_managers", "collaborators"] if (multiple_names or has_keywords) else ["primary_executive", "product_managers"]
return {**state, "columns_to_search": columns}
class QueryOutput(TypedDict):
query: Annotated[str, ..., "Syntactically valid SQL query."]
def write_query(state: State):
prompt_args = {
"dialect": db.dialect,
"top_k": 10,
"table_info": db.get_table_info(),
"columns_to_search": ", ".join(state.get("columns_to_search", [])) if "columns_to_search" in state else "",
"input": state["question"],
}
prompt = custom_query_prompt.invoke(prompt_args)
result = llm.with_structured_output(QueryOutput).invoke(prompt)
print("write_query")
return {"query": result["query"]}
def execute_query(state: State):
print("execute_query")
return {"result": QuerySQLDatabaseTool(db=db).invoke(state["query"])}
async def generate_answer(state: State):
prompt = (
"Given the following user question, executed SQL query, and SQL result, "
"answer the user's question based only on the SQL result.\n\n"
"You must answer in Russian language.\n\n"
f"User Question:\n{state['question']}\n\n"
f"Executed SQL Query:\n{state['query']}\n\n"
f"SQL Result:\n{state['result']}\n\n"
"Now write a complete and understandable answer in Russian."
)
print("generate_answer")
response = await llm.ainvoke(prompt)
return {"answer": response.content}
graph_builder = StateGraph(State)
graph_builder.add_node("resolve_name", resolve_name)
graph_builder.add_node("analyze_question_for_role", analyze_question_for_role)
graph_builder.add_node("write_query", write_query)
graph_builder.add_node("execute_query", execute_query)
graph_builder.add_node("generate_answer", generate_answer)
graph_builder.add_edge(START, "resolve_name")
graph_builder.add_edge("resolve_name", "analyze_question_for_role")
graph_builder.add_edge("analyze_question_for_role", "write_query")
graph_builder.add_edge("write_query", "execute_query")
graph_builder.add_edge("execute_query", "generate_answer")
graph = graph_builder.compile()
import asyncio
async def ask_stream(question: str):
async for event in graph.astream_events({"question": question}, version="v2"):
kind = event["event"]
if kind == "on_chat_model_stream":
print(event["data"]["chunk"].content, end="", flush=True)
elif kind == "on_tool_end":
output = event["data"].get("output")
if output:
print(f"\n[Tool Output]: {output}\n")
print("\n\n✅ Ответ завершён.")
С помощью LangChain и LangGraph вы можете:
- быстро разрабатывать кастомных LLM-ассистентов,
- автоматизировать SQL-доступ к данным,
- использовать приватные LLM без передачи данных в облако.
Эта система — основа для внедрения умного чат-бота в корпоративной BI-экосистеме.
 Share
Share