Публикация была переведена автоматически. Исходный язык: Русский


Добрый день читателям Astana Hub.
Я студент, как и многие студенты, по городу я передвигаюсь в основном на автобусе. Идея поста возникла, когда одним прекрасным днём стоя на остановке и ожидая свой заветный автобус и судорожно посматривая на его местоположение в приложении AstraBUS (приложение отображает онлайн местоположение автобусов столицы). Я подумал, почему бы не сделать свою независимую мини - оценку общественного транспорта нашей столицы. Со всеми графиками и картами. Сказано - Сделано.
Для начала мне как-то нужно было собрать эти исходные данные. Использовав PacketCapture (приложение для анализа трафика) заметил, что в их API есть endpoint , который зная номер автобуса выдает текущее местоположение всех автобусов с их координатами и их углом поворота относительно севера (дирекционный угол).
 рис. 1. скрин с PacketCapture
рис. 1. скрин с PacketCapture
То что мне нужно. К сожалению, данный сервис не позволяет просмотреть вчерашние или прошлогодние данные, хотя по мне данный инструмент пользовался бы спросом у аналитиков и транспортников. Ну раз realtime так realtime.
Так как стоит задача именно проанализировать данные, соответственно, сначала нужно эти данные как-то достать. Пишем парсер для скачивания и сохранения данных:
1. Импортируем библиотеки и создаем список с номерами автобусов
import requests
import time
import json
import csv
from datetime import datetime
bus_numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17,
18, 19, 20, 21, 22, 23, 24, 25, 28, 29, 31, 32, 34, 35, 36,
37, 39, 40, 41, 44, 46, 47, 48, 50, 51, 52, 53, 54, 56, 60,
61, 64, 70, 71, 72, 73, 80, 81, 120]
2. Основной скрипт довольно прост ; пробегаемся циклом по массиву bus_numbers и сохраняем всё в файл csv. Ссылку на github со всеми исходниками прикреплю ниже.
def parser(iter, bus_number):
url = BUS_COORDINATE_API+str(bus_number)
r = requests.get(url, headers=headers)
bus_dict = json.loads(r.text)
bus_list = []
for key in bus_dict:
x = {"bus_id": key, 'iter': iter}
z = {**bus_dict[key], **x}
bus_list.append(z)
save_to_csv(bus_list, bus_number)
def save_to_csv(bus_list, bus_number):
filename = 'bus/'+'bus_' + str(bus_number) + ".csv"
with open(filename, 'a+') as outfile:
fieldnames = ['bus_id', 'route', 'time',
'latitude', 'longitude', 'angle', 'iter']
writer = csv.DictWriter(outfile, fieldnames=fieldnames)
for bus in bus_list:
writer.writerow(bus)
def main():
try:
global iteration
for bus in bus_numbers:
parser(iteration, bus)
iteration += 1
except:
print("Some problems with connection", datetime.now())
Результат скрипта выше это - 50 файлов csv записанные с интервалом в одну минуту на каждый маршрут. 7 - колонка - это данные с итерацией , которые показывают время прошедшее с начала работы скрипта(т.е каждую минуту).
7 апреля поставил скрипт работать с 9 утра и вечером к часам к 11 отключил. Результат смотреть на рисунке ниже:
![]() рис.2. Пример файлов с данными автобусов
рис.2. Пример файлов с данными автобусов
Данные есть. Дополнительно скачал данные о существующих остановках с OpenStreetMap.
Каждый маршрут выглядит как множества точек, лежащих на одной мульти-линии с атрибутивными данными как время и уникальный идентификатор каждого автобуса (см. рис. 3).
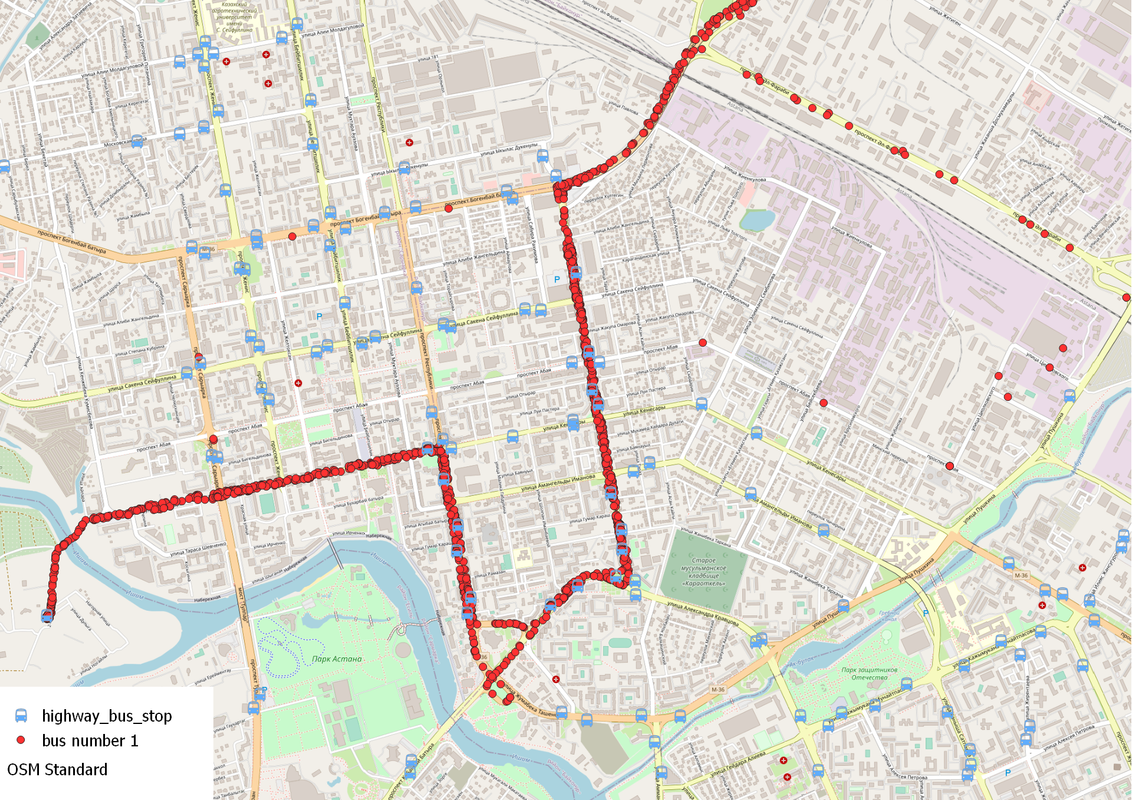 рис. 3. Пример маршрута №1
рис. 3. Пример маршрута №1
Создаем БД в PostgreSQL
Для того что бы вычислить среднее время задержки какого либо автобуса нужно вычислить его интервал. Т.е взять точки остановок, построить круглый буфер вокруг остановок и считать входящие туда автобусы и вычислить, в каком порядке и в какое время автобусы проезжали остановку.
На этом этапе возникла потребность как-то правильно агрегировать имеющиеся данные и чтобы не изобретать велосипед решено было пересохранить все данные, реляционную базу данных PostgreSQL для того, чтобы в дальнейшем применять на нем пространственные инструменты через PostGIS (такие как построение буфера вокруг точек и подсчет количества входящих туда автобусов рис. 4).

рис. 4 . Буфер вокруг остановок
В целом структура базы данных выглядит довольно просто, две основные таблицы и вспомогательная - для хранения времени задержки с отношением один ко многим.

рис. 5. Схема бд
Снизу пример SQL запроса на создания таблицы bus
CREATE TABLE IF NOT EXISTS bus (id serial PRIMARY KEY, bus_id varchar, route_number varchar, latest_bus_stop_id integer, iteration integer, time_at timestamp, pt geometry);
поле pt с типом geometry это поле для хранения пространственной информации автобуса и остановки. Таблицы созданы, осталось переписать их в БД. Пишем скрипт для пересохранения данных с csv в postgres:
def insert_row_to_db(row):
insert_query = """ INSERT INTO bus (bus_id,route_number,time_at, iteration, pt)
VALUES (%s, %s, %s, %s, ST_GeomFromText(%s, 4326))"""
date_time_obj = datetime.strptime(row[2],'%Y-%m-%d %H:%M:%S')
point = "POINT({} {})".format(row[4],row[3])
item_tuple = (row[0],row[1],date_time_obj,row[6],point)
cursor.execute(insert_query, item_tuple)
conn.commit()
#csv contain 7 columns
def insert_bus_to_db(path):
with open(path) as file:
file = csv.reader(file,delimiter = ',')
for row in file:
insert_row_to_db(row)
def save_bus_to_db():
for bus in bus_numbers:
path = bus_data_path + str(bus)+".csv"
insert_bus_to_db(path)
def insert_bus_stop_row_to_db(row):
insert_query = """ INSERT INTO bus_stop (pt)
VALUES (ST_GeomFromText(%s, 4326))"""
point = "POINT({} {})".format(row[1],row[2])
item_tuple = (point,)
cursor.execute(insert_query, item_tuple)
conn.commit()
def insert_bus_stop_to_db():
with open("./bus/bus_stops/bus_stops.csv") as file:
file = csv.reader(file,delimiter = ',')
for row in file:
insert_bus_stop_row_to_db(row)В целом получилось примерно 320 тысяч записей это только данные на 7 апреля. А сама БД со всеми таблицами весит 66 МБ.
 рис. 6 . Админ панель Postgresql
рис. 6 . Админ панель Postgresql
Пишем SQL запросы
Переходим к расчету и написанию PostgreSQL/Postgis запросов.
C Postgis нам нужны только две функции это ST_Buffer и ST_Contains (для построения буфера и проверки вхождения элементов внутрь буфера).
Записывать задержки будем в таблицу bus_stop_delay_history . Алгоритм на псевдокоде таков:
Для каждой итерации :
проверить входит ли автобус в буферную зону остановки, если входит:
запиши в bus_stop_delay_history время вхождения и в поле delay отними текущее значение времени от предыдущего
иначе:
пропусти
Пример SQL запроса на создания буфера и проверки вхождения автобуса в буфер на первую итерацию:
select bus.*,bus_stop.* from bus, bus_stop where ST_contains(ST_Buffer(bus_stop.pt,0.0008,'quad_segs=8'),bus.pt) and (bus.iteration = 1) and (bus.latest_bus_stop_id is null or bus.latest_bus_stop_id != bus_stop.id);
Занятный факт: В столице всего 539 уникальных автобусов (по крайней со включенным GPS). Простой SQL запрос показывает все уникальные автобусы курсирующие в 9:30 утра
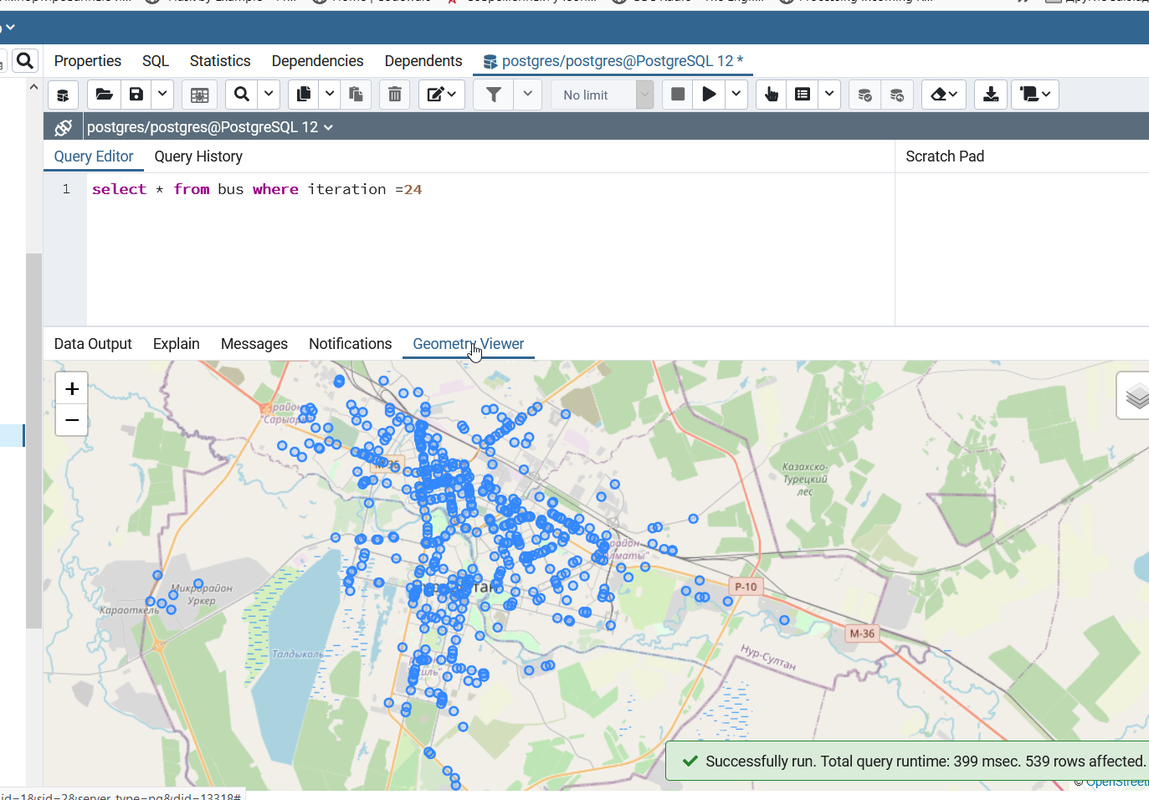 рис. 7. Все автобусы в столице в 9:30
рис. 7. Все автобусы в столице в 9:30
Визуализация и выводы
Визуализировать результаты буду через библиотеку Matplotlib. Код примера ниже.
from matplotlib.dates import DateFormatter
import matplotlib.dates as dates
import numpy as np
fig, ax = plt.subplots()
ax.plot_date(x, y,"b-", label="№2")
ax.xaxis.set_major_formatter(dates.DateFormatter('%H:%M'))
y_mean = [np.mean(y)]*len(x)
ax.plot_date(x, y_mean,"b--", label="№2 среднее")
plt.title('Хронология времени задержки автобусов на остановке "Парк Жабаева"')
plt.ylabel('Время задержки в минутах')
plt.xlabel('Время (часов)')
plt.legend()
plt.show()В целом можно сделать отдельный аудит - проверку на каждую остановку и каждый маршрут
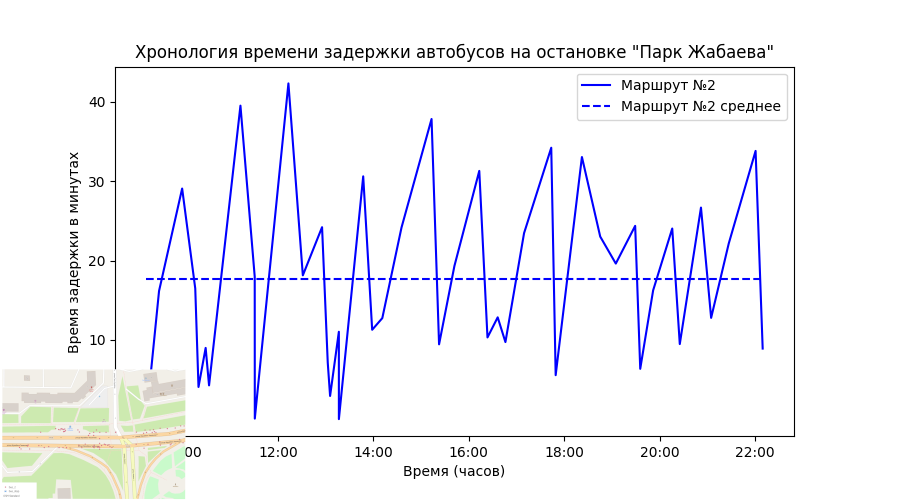 рис. 8
рис. 8
Есть одна большая ошибка в моей оценке. Заключается она в том, что происходит двойная запись автобусов. Т.е когда автобус из точки А проезжает в точку С, посередине стоящая остановка Б записывает время, когда автобус подъехал и забрал пассажиров - с этим всё ОК. Но когда другой автобус, проезжающий на противоположной линии маршрута из точки С едит в точку А и подъезжает к остановке Б, происходит еще одна запись. Данную погрешность можно исправить, если знать текущий дирекционный угол автобуса и учитывать ее при записи задержки, но так как целью данного поста не является точная оценка, данный момент я пропустил и просто использовал среднее значение.
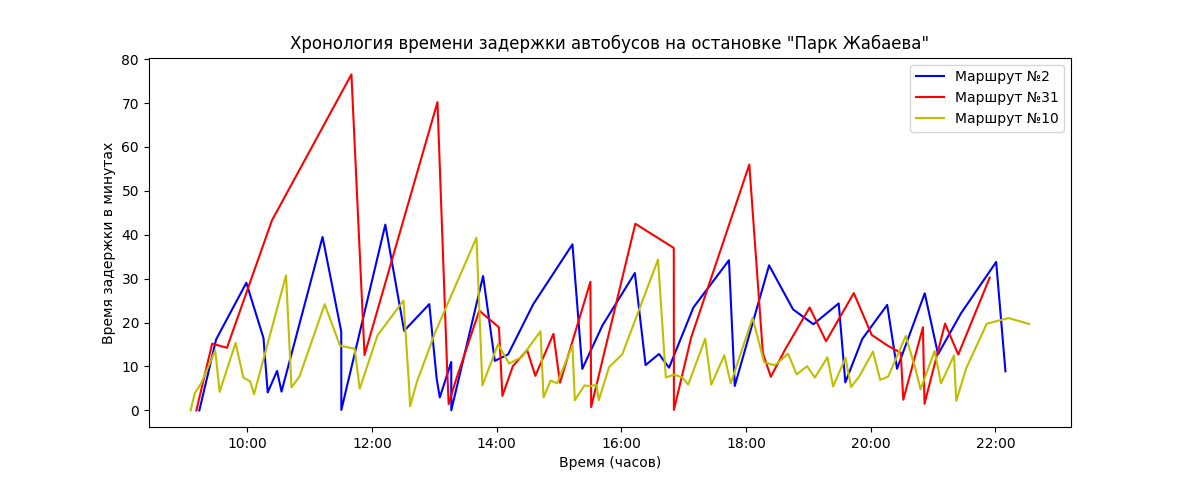 рис. 9. У №10 очень небольшой интервал подачи автобуса
рис. 9. У №10 очень небольшой интервал подачи автобуса
В среднем автобусы в столице движутся с интервалом 22 минуты. В центре города чаще, но на периферии есть автобусы с задержкой 40 минут.
Я думаю, что пост получился информативный и полезный. В планах дополнительно сделать интерактивную карту, которая покажет проблемные маршруты на дорогах и выявить возможные причины задержки.
Спасибо за прочтение. Вы так же можете попробовать оценить ситуацию с автобусами проезжающие на вашей остановке скачав мой репозитории на GitHub и повторив действия выше.
Добрый день читателям Astana Hub.
Я студент, как и многие студенты, по городу я передвигаюсь в основном на автобусе. Идея поста возникла, когда одним прекрасным днём стоя на остановке и ожидая свой заветный автобус и судорожно посматривая на его местоположение в приложении AstraBUS (приложение отображает онлайн местоположение автобусов столицы). Я подумал, почему бы не сделать свою независимую мини - оценку общественного транспорта нашей столицы. Со всеми графиками и картами. Сказано - Сделано.
Для начала мне как-то нужно было собрать эти исходные данные. Использовав PacketCapture (приложение для анализа трафика) заметил, что в их API есть endpoint , который зная номер автобуса выдает текущее местоположение всех автобусов с их координатами и их углом поворота относительно севера (дирекционный угол).
рис. 1. скрин с PacketCapture
То что мне нужно. К сожалению, данный сервис не позволяет просмотреть вчерашние или прошлогодние данные, хотя по мне данный инструмент пользовался бы спросом у аналитиков и транспортников. Ну раз realtime так realtime.
Так как стоит задача именно проанализировать данные, соответственно, сначала нужно эти данные как-то достать. Пишем парсер для скачивания и сохранения данных:
1. Импортируем библиотеки и создаем список с номерами автобусов
import requests
import time
import json
import csv
from datetime import datetime
bus_numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17,
18, 19, 20, 21, 22, 23, 24, 25, 28, 29, 31, 32, 34, 35, 36,
37, 39, 40, 41, 44, 46, 47, 48, 50, 51, 52, 53, 54, 56, 60,
61, 64, 70, 71, 72, 73, 80, 81, 120]
2. Основной скрипт довольно прост ; пробегаемся циклом по массиву bus_numbers и сохраняем всё в файл csv. Ссылку на github со всеми исходниками прикреплю ниже.
def parser(iter, bus_number):
url = BUS_COORDINATE_API+str(bus_number)
r = requests.get(url, headers=headers)
bus_dict = json.loads(r.text)
bus_list = []
for key in bus_dict:
x = {"bus_id": key, 'iter': iter}
z = {**bus_dict[key], **x}
bus_list.append(z)
save_to_csv(bus_list, bus_number)
def save_to_csv(bus_list, bus_number):
filename = 'bus/'+'bus_' + str(bus_number) + ".csv"
with open(filename, 'a+') as outfile:
fieldnames = ['bus_id', 'route', 'time',
'latitude', 'longitude', 'angle', 'iter']
writer = csv.DictWriter(outfile, fieldnames=fieldnames)
for bus in bus_list:
writer.writerow(bus)
def main():
try:
global iteration
for bus in bus_numbers:
parser(iteration, bus)
iteration += 1
except:
print("Some problems with connection", datetime.now())
Результат скрипта выше это - 50 файлов csv записанные с интервалом в одну минуту на каждый маршрут. 7 - колонка - это данные с итерацией , которые показывают время прошедшее с начала работы скрипта(т.е каждую минуту).
7 апреля поставил скрипт работать с 9 утра и вечером к часам к 11 отключил. Результат смотреть на рисунке ниже:
![]() рис.2. Пример файлов с данными автобусов
рис.2. Пример файлов с данными автобусов
Данные есть. Дополнительно скачал данные о существующих остановках с OpenStreetMap.
Каждый маршрут выглядит как множества точек, лежащих на одной мульти-линии с атрибутивными данными как время и уникальный идентификатор каждого автобуса (см. рис. 3).
рис. 3. Пример маршрута №1
Создаем БД в PostgreSQL
Для того что бы вычислить среднее время задержки какого либо автобуса нужно вычислить его интервал. Т.е взять точки остановок, построить круглый буфер вокруг остановок и считать входящие туда автобусы и вычислить, в каком порядке и в какое время автобусы проезжали остановку.
На этом этапе возникла потребность как-то правильно агрегировать имеющиеся данные и чтобы не изобретать велосипед решено было пересохранить все данные, реляционную базу данных PostgreSQL для того, чтобы в дальнейшем применять на нем пространственные инструменты через PostGIS (такие как построение буфера вокруг точек и подсчет количества входящих туда автобусов рис. 4).
рис. 4 . Буфер вокруг остановок
В целом структура базы данных выглядит довольно просто, две основные таблицы и вспомогательная - для хранения времени задержки с отношением один ко многим.
рис. 5. Схема бд
Снизу пример SQL запроса на создания таблицы bus
CREATE TABLE IF NOT EXISTS bus (id serial PRIMARY KEY, bus_id varchar, route_number varchar, latest_bus_stop_id integer, iteration integer, time_at timestamp, pt geometry);
поле pt с типом geometry это поле для хранения пространственной информации автобуса и остановки. Таблицы созданы, осталось переписать их в БД. Пишем скрипт для пересохранения данных с csv в postgres:
def insert_row_to_db(row):
insert_query = """ INSERT INTO bus (bus_id,route_number,time_at, iteration, pt)
VALUES (%s, %s, %s, %s, ST_GeomFromText(%s, 4326))"""
date_time_obj = datetime.strptime(row[2],'%Y-%m-%d %H:%M:%S')
point = "POINT({} {})".format(row[4],row[3])
item_tuple = (row[0],row[1],date_time_obj,row[6],point)
cursor.execute(insert_query, item_tuple)
conn.commit()
#csv contain 7 columns
def insert_bus_to_db(path):
with open(path) as file:
file = csv.reader(file,delimiter = ',')
for row in file:
insert_row_to_db(row)
def save_bus_to_db():
for bus in bus_numbers:
path = bus_data_path + str(bus)+".csv"
insert_bus_to_db(path)
def insert_bus_stop_row_to_db(row):
insert_query = """ INSERT INTO bus_stop (pt)
VALUES (ST_GeomFromText(%s, 4326))"""
point = "POINT({} {})".format(row[1],row[2])
item_tuple = (point,)
cursor.execute(insert_query, item_tuple)
conn.commit()
def insert_bus_stop_to_db():
with open("./bus/bus_stops/bus_stops.csv") as file:
file = csv.reader(file,delimiter = ',')
for row in file:
insert_bus_stop_row_to_db(row)В целом получилось примерно 320 тысяч записей это только данные на 7 апреля. А сама БД со всеми таблицами весит 66 МБ.
рис. 6 . Админ панель Postgresql
Пишем SQL запросы
Переходим к расчету и написанию PostgreSQL/Postgis запросов.
C Postgis нам нужны только две функции это ST_Buffer и ST_Contains (для построения буфера и проверки вхождения элементов внутрь буфера).
Записывать задержки будем в таблицу bus_stop_delay_history . Алгоритм на псевдокоде таков:
Для каждой итерации :
проверить входит ли автобус в буферную зону остановки, если входит:
запиши в bus_stop_delay_history время вхождения и в поле delay отними текущее значение времени от предыдущего
иначе:
пропусти
Пример SQL запроса на создания буфера и проверки вхождения автобуса в буфер на первую итерацию:
select bus.*,bus_stop.* from bus, bus_stop where ST_contains(ST_Buffer(bus_stop.pt,0.0008,'quad_segs=8'),bus.pt) and (bus.iteration = 1) and (bus.latest_bus_stop_id is null or bus.latest_bus_stop_id != bus_stop.id);
Занятный факт: В столице всего 539 уникальных автобусов (по крайней со включенным GPS). Простой SQL запрос показывает все уникальные автобусы курсирующие в 9:30 утра
рис. 7. Все автобусы в столице в 9:30
Визуализация и выводы
Визуализировать результаты буду через библиотеку Matplotlib. Код примера ниже.
from matplotlib.dates import DateFormatter
import matplotlib.dates as dates
import numpy as np
fig, ax = plt.subplots()
ax.plot_date(x, y,"b-", label="№2")
ax.xaxis.set_major_formatter(dates.DateFormatter('%H:%M'))
y_mean = [np.mean(y)]*len(x)
ax.plot_date(x, y_mean,"b--", label="№2 среднее")
plt.title('Хронология времени задержки автобусов на остановке "Парк Жабаева"')
plt.ylabel('Время задержки в минутах')
plt.xlabel('Время (часов)')
plt.legend()
plt.show()В целом можно сделать отдельный аудит - проверку на каждую остановку и каждый маршрут
рис. 8
Есть одна большая ошибка в моей оценке. Заключается она в том, что происходит двойная запись автобусов. Т.е когда автобус из точки А проезжает в точку С, посередине стоящая остановка Б записывает время, когда автобус подъехал и забрал пассажиров - с этим всё ОК. Но когда другой автобус, проезжающий на противоположной линии маршрута из точки С едит в точку А и подъезжает к остановке Б, происходит еще одна запись. Данную погрешность можно исправить, если знать текущий дирекционный угол автобуса и учитывать ее при записи задержки, но так как целью данного поста не является точная оценка, данный момент я пропустил и просто использовал среднее значение.
рис. 9. У №10 очень небольшой интервал подачи автобуса
В среднем автобусы в столице движутся с интервалом 22 минуты. В центре города чаще, но на периферии есть автобусы с задержкой 40 минут.
Я думаю, что пост получился информативный и полезный. В планах дополнительно сделать интерактивную карту, которая покажет проблемные маршруты на дорогах и выявить возможные причины задержки.
Спасибо за прочтение. Вы так же можете попробовать оценить ситуацию с автобусами проезжающие на вашей остановке скачав мой репозитории на GitHub и повторив действия выше.


