Бұл жазба автоматты түрде аударылған. Бастапқы тіл: Орысша



1. Кіріспе
Соңғы жылдары әртүрлі тілдердегі мәтіндерді түсінуге және құруға қабілетті тілдік модельдердің қарқынды дамуы байқалды. Дегенмен, қазақ тілі үшін әлі де жоғары сапалы ашық модельдер мен датасеттер саны шектеулі, бұл неғұрлым кең таралған тілдерде (ағылшын, қытай, орыс және т.б.) оқытылған модельдермен салыстыруға болатын нәтижелерге қол жеткізуді айтарлықтай қиындатады.
Бұл мақалада біз қазақ тіліндегі модельді файн-тюнинг тәжірибесін қарастырамыз, оның құны шамамен 10 АҚШ долларын (немесе 5000 теңге) құрады және A100 графикалық процессорының көмегімен жүргізілді. Біз алынған нәтижелерді ұзақ уақыт бойы қымбат есептеу ресурстарында оқыған модельмен салыстырамыз және сауатты тәсілмен тіпті бюджеттік оқыту салыстырмалы нәтижелер бере алатынын көрсетеміз. Сонымен қатар, біз деректер жиынтығын кеңейту және параметрлер санын үлкен масштабқа (шамамен 3 миллиард) дейін арттыру арқылы модель сапасын одан әрі жақсартудың ықтимал жолдарын қысқаша атап өтеміз.
2. Қолданыстағы шешімдерге шолу
2.1 модель-"сілтеме": ISSAI/LLama-3.1-KazLLM-1.0-8B
Hugging Face сайтында қолжетімді қазақ тіліне арналған белгілі ашық модельдердің бірі issai / LLama-3.1-Kazllm-1.0-8B болып табылады. бұл модель, авторлардың айтуынша, ұзақ уақыт бойы және мамандандырылған аппараттық құралдарда оқытылған. Ол бірнеше қазақ тілді тест жиынтықтарында (MMLU-тәрізді және басқалары) жоғары дәлдікті көрсетеді.
2.2 жаңа модель: armanibadboy / llama3. 1-kazllm-8b-by-arman-ver2
Біздің модель үшін негіз ретінде unsloth/Meta-Llama-3.1-8B-Instruct репозиторийі алынды, содан кейін қазақ тілінде жеке Файн-тюнинг өткізілді. Жалпы оқу шығындары шамамен 5000 теңгені (~10 АҚШ доллары) құрады және қорытынды модель Hugging Face сайтында орналастырылған. Оқыту үшін A100 GPU қолданылды, бұл процесті жылдамдатуға және жад пен есептеу жылдамдығына байланысты кейбір шектеулерді айналып өтуге мүмкіндік берді.
3. Пайдаланылған деректер жиынтығы
3.1 финді баптауға арналған негізгі деректер жиынтығы
Біздің эксперименттің бір бөлігі ретінде біз Hugging Face - те қол жетімді дайын деректер жиынтығына сүйендік:
1. kz-transformers/mmlu-translated – kk-қазақ тіліне аударылған MMLU фрагменті.
2. kz-transformers/kazakh-dastur – Mc-заңнама негіздері бойынша тест тапсырмалары ("Дәстүр").
3. kz-transformers/Kazakh-constitution – Mc-Конституция бойынша тест тапсырмалары.
4. kz-transformers/Kazakh-unified-National-testing – MC-ҰБТ бойынша сұрақтар жинағы (тарих, география, ағылшын, биология және т.б. сияқты пәндер).
Оқуды жеңілдету үшін бұл деректер жиындары біріктіріліп, нұсқау-жауап пішіміне (prompt + дұрыс жауап) "өзгертілді".
3.2 деректерді кеңейтудің қосымша перспективалары
Масштабты ұлғайту және осылайша сапаны жақсарту үшін оқытуға біріктіруге болатын басқа деректер жиындары бар:
* saillab/alpaca-Kazakh-cleaned – alpaca стиліндегі нұсқаулар жиынтығының қазақша нұсқасы.
* wikimedia / wikipedia (Ішкі жиын 20231101.kk) - Қазақ Уикипедиясының соңғы түсірілімі.
Осы датасеттерді (әсіресе Википедияны) қосқанда, оқу үлгісінің көлемі бірнеше есе артуы мүмкін. Нәтижесінде, егер сіз модельдің масштабын ұлғайтсаңыз (мысалы, параметрлер санын 3 млрд-қа дейін жеткізсеңіз), сіз одан да жақсы нәтижелерге сене аласыз. Алайда, мұндай кеңейту Енді Google Colab-ты ғана емес, сонымен қатар күрделі есептеу қуатын (мысалы, арнайы серверлер немесе кластерлер) қажет етеді, өйткені Colab әрдайым фондық режимде жұмыс істеуге мүмкіндік бермейді; және "автотұрақ" өшірілген тарифтер айтарлықтай қымбатқа түседі (айына~49 доллар және одан жоғары).
. Финді баптау әдістері мен процесі
4.1 бастапқы модель және қоршаған орта
* Бастапқы модель: unsloth/Meta-Llama-3.1-8B-Нұсқаулық.
* Финді баптау:
* Google colab Pro қызметі арқылы A100 GPU қолданылды
* Жалпы шығыстар-шамамен 5000 теңге (10 АҚШ доллары). 100 токен сатып алынды бұл 14 сағаттық оқуға жеткілікті
4.2 Оқытудың техникалық аспектілері
* Hugging Face Transformers және peft жақтауы" жеңіл " оқыту үшін пайдаланылды (LoRA/QLoRA және т.б.).
* Датасеттерді "Нұсқаулық" форматына құрастыру, әртүрлі жиынтықтарды біріктіру, артық динамиктерді жою және т.б.
* Гиперпараметрлерді (batch_size, learning rate, epochs және т.б.) VRAM және уақыт шектеулерінен асып кетпеу үшін теңшеу.
5. Сапаны бағалау (Evaluation)
5.1 тапсырмалар жиынтығы және көрсеткіштер
Бағалау үшін біз lm_eval сценарийін келесі тапсырмалар жиынтығымен қолдандық (MMLU тәрізді және UNT-бағытталған):
• mmlu_translated_kk
• kazakh_and_literature_unt_mc
• kk_biology_unt_mc
• kk_constitution_mc
• kk_dastur_mc
• kk_english_unt_mc
• kk_geography_unt_mc
• kk_history_of_kazakhstan_unt_mc
• kk_human_society_rights_unt_mc
• kk_unified_national_testing_mc
• kk_world_history_unt_mc
Негізгі метрика-дұрыс жауаптардың пайызын көрсететін accuracy (acc) (zero-shot режимі, --num_fewshot 0).
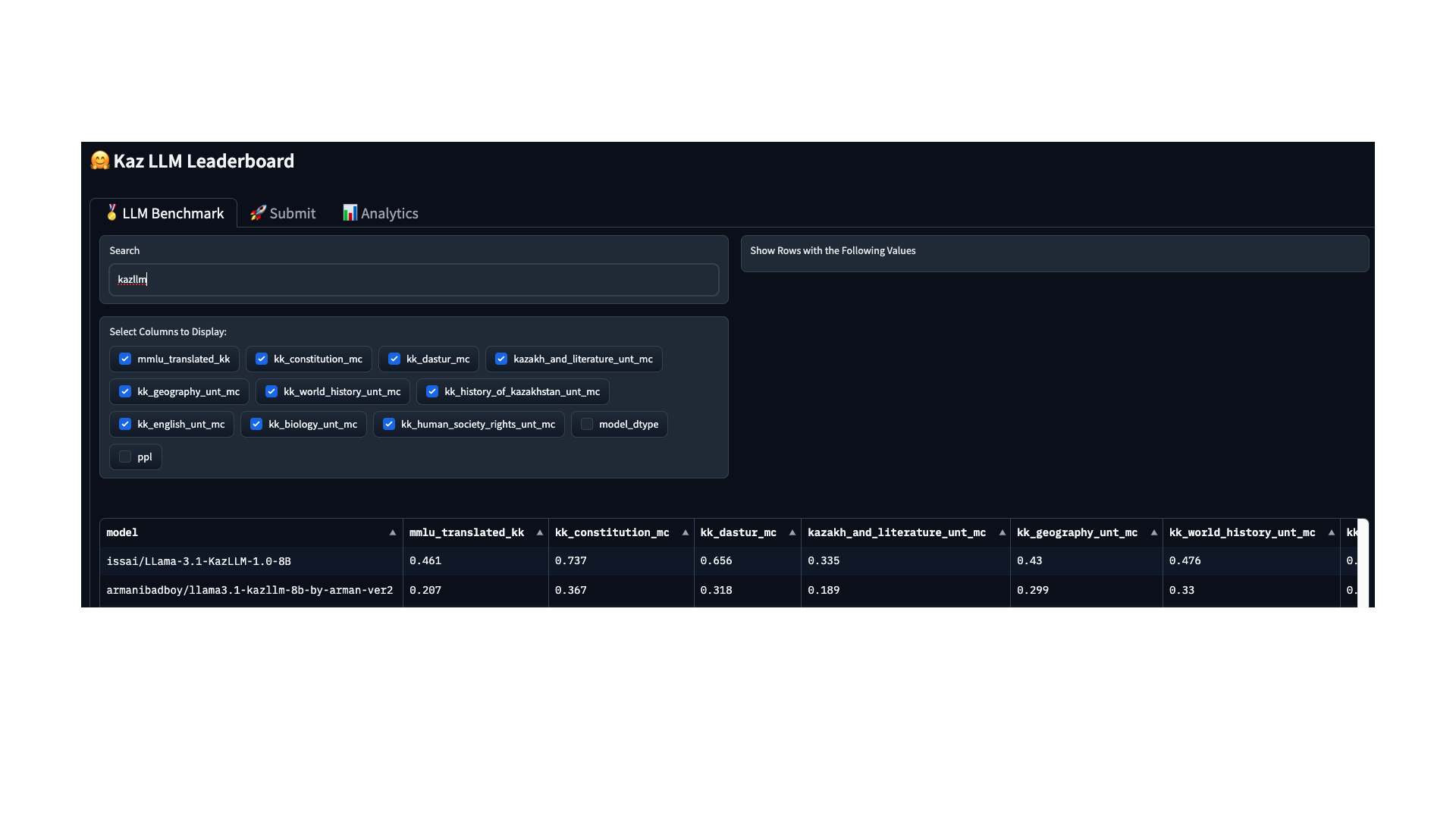
5.2 нәтижелер
Үлгі: armanibadboy/llama3. 1-kazllm-8b-by-arman-ver2
| Тапсырма | acc | ± (stderr) |
| kazakh_and_literature_unt_mc | 0,1893 | ±0.0067 |
| kk_biology_unt_mc | 0,2263 | ±0.0115 |
| kk_constitution_mc | 0,3667 | ±0.0312 |
| kk_dastur_mc | 0,3177 | ±0.0202 |
| kk_english_unt_mc | 0,2797 | ±0.0104 |
| kk_geography_unt_mc | 0,2987 | ±0.0145 |
| kk_history_of_kazakhstan_unt_mc | 0,232 | ±0.0086 |
| kk_human_society_rights_unt_mc | 0,4362 | ±0.0408 |
| kk_unified_national_testing_mc | 0,2263 | ±0.0115 |
| kk_world_history_unt_mc | 0,3299 | ±0.0145 |
| mmlu_translated_kk | 0,207 | ±0.0120 |
Салыстыру: issai/LLama-3.1-KazLLM-1.0-8B (сол параметрлерде)
| Тапсырма | acc | ± (stderr) |
| kazakh_and_literature_unt_mc | 0,2088 | ±0.0070 |
| kk_biology_unt_mc | 0,2733 | ±0.0123 |
| kk_constitution_mc | 0,4417 | ±0.0321 |
| kk_dastur_mc | 0,359 | ±0.0208 |
| kk_english_unt_mc | 0,3254 | ±0.0109 |
| kk_geography_unt_mc | 0,3716 | ±0.0153 |
| kk_history_of_kazakhstan_unt_mc | 0,2943 | ±0.0093 |
| kk_human_society_rights_unt_mc | 0,4899 | ±0.0411 |
| kk_unified_national_testing_mc | 0,2733 | ±0.0123 |
| kk_world_history_unt_mc | 0,3782 | ±0.0149 |
| mmlu_translated_kk | 0,2991 | ±0.0135 |
Көріп отырғаныңыздай, armanibadboy/llama3.1-kazllm-8B-by-arman-ver2 моделі салыстырмалы түрде жылдам және небәрі 5000 теңгеге оқытылған, бірқатар міндеттерде ISSAI/llama-3.1-kazllm-1.0-8B "ересек" моделінен онша төмен емес нәтижелерді көрсетеді. алшақтық байқалды, бірақ оны тұңғиық деп атауға болмайды — әсіресе бізде арнайы серверлер мен көп сағаттық оқу уақыты болмағандықтан.
6. Кейбір көшбасшылармен сәйкессіздіктердің себептері
Әр түрлі қоғамдық лидербордтармен салыстырғанда көрсеткіштерде айтарлықтай сәйкессіздіктерді анықтауға болады (ISSAI/LLama-3.1-Kazllm-1.0-8B және басқа модельдер үшін). Төменде негізгі факторлар келтірілген:
1. Dataset нұсқалары. Лидербордтарда тест жиынтықтарының басқа нұсқалары немесе арнайы сүзу қолданылуы мүмкін.
2. Әр түрлі бағалау параметрлері. Few-shot мысалдарының саны, temperature, top_p және басқа генерация параметрлері нәтижеге әсер етуі мүмкін.
3. Модель жаңартулары. Авторлар кейде жаңа салмақтарды немесе қайта оқытылған нұсқаларды шығарады.
4. Ең жақсы жүгіруді таңдау. Кейбір жағдайларда орташа нәтижелердің орнына" жақсы " нәтижелер жарияланады.
Lm_eval арқылы алған ISSAI/LLama-3.1-KazLLM-1.0-8B моделінің мәндері осы бетте көрсетілген көрсеткіштерден айтарлықтай ерекшеленетініне назар аударғым келеді. Лидербордтың айтуынша, модель әлдеқайда жоғары нәтиже көрсетеді.
Осыған байланысты, менің моделім екі есе төмен болып көрінуі мүмкін, дегенмен көрсетілген ресурста Көрсетілген сынақтарды іске қосқан кезде модельдер арасындағы айырмашылық онша байқалмайды.
Егер осы лидербордтың иесі осы жолдарды оқыса, беттегі нәтижелерді жаңартыңыз. Мен, жарысты жақсы көретін адам ретінде, ең өзекті деректерді көргім келеді және шынымен дұрыс салыстыруларға сүйенгім келеді.**
7. Қорытындылар және одан әрі жұмыс
1. Үнемді күйге келтіру. Эксперимент көрсеткендей, тіпті ~10 АҚШ долларына (5000 теңге) A100 GPU бар Google Colab көмегімен Қазақ тілі моделі үшін жеткілікті жақсы нәтижелерге қол жеткізуге болады.
2. Жақын нәтижелер. Біздің модель мен "ауыр" (issai/llama-3.1-KazLLM-1.0-8B) арасындағы айырмашылық әлі де бар, бірақ шығындар мен Оқу уақытының көптігін ескере отырып, онша маңызды емес.
3. Деректер жиынын кеңейту және параметрлерді ұлғайту. Сапаны одан әрі жақсарту үшін қосымша деректер жиынтығын қосуға болады-мысалы, saillab/alpaca-Kazakh-cleaned немесе wikimedia/wikipedia (subset 20231101.kk). Осы көздердің барлығын қосу деректер көлемін бірнеше гигабайтқа дейін арттыруы мүмкін, бұл өз кезегінде модельді (~3b параметрлеріне дейін және одан жоғары) арттыруға мүмкіндік береді. Алайда, бұл жерде арнайы серверлер немесе бұлтты қызметтер Colab-қа қарағанда қымбатырақ болады, өйткені Google Colab-та сеанс уақыты мен жад көлеміне шектеулер бар, ал ажыратылмайтын режим айына шамамен 49 доллар және одан жоғары тұрады.
4. Лидербордтарды жаңарту. Қазақ тілді LLM-модельдер саласындағы жылдам ілгерілеуді ескере отырып, жаңа және жаңартылған модельдердің нақты көрсеткіштерін көрсету үшін көшбасшылардың ресми кестелерінің нәтижелерін мезгіл-мезгіл жаңартып отыру маңызды.
Қолданба: эксперимент коды
Төменде біз модельді оқыту және бағалау үшін қолданған код (A100 GPU бар ортада іске қосылды). Сіз өзіңіздің қажеттіліктеріңізге бейімделе аласыз, гиперпараметрлер мен деректер жиынтығын өзгерте аласыз.
%%capture
!pip install unsloth
# Сонымен қатар репозиторийден Unsloth бағдарламасының соңғы нұсқасын орнатыңыз
!pip uninstall unsloth -y && pip install --upgrade --no-cache-dir --no-deps git+https://github.com/unslothai/unsloth.git
from unsloth import FastLanguageModel
import torch
max_seq_length = 2048
dtype = None # автоматты анықтау ( Float16, BFloat16 және т. б. орнатуға болады)
load_in_4bit = false # True қажет болған жағдайда 4bit-кванттау
# 4-биттік модельдер тізімі (қажет болса)
fourbit_models = [
"unsloth/Meta-Llama-3.1-8B-bnb-4bit",
"unsloth/Meta-Llama-3.1-8B-Instruct-bnb-4bit",
# ...
]
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/Meta-Llama-3.1-8B-Instruct",
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
)
# LoRA Орнату
model = FastLanguageModel.get_peft_model(
model,
r = 32,
target_modules = [
"q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",
],
lora_alpha = 32,
lora_dropout = 0,
bias = "none",
use_gradient_checkpointing = "unsloth",
random_state = 3407,
use_rslora = False,
loftq_config = None,
)
# Деректерді жүктеу және дайындау
from datasets import load_dataset, concatenate_datasets
dataset = load_dataset("kz-transformers/mmlu-translated-kk")
dataset3 = load_dataset("kz-transformers/kazakh-dastur-mc", split='test')
dataset2 = load_dataset("kz-transformers/kazakh-constitution-mc", split='test')
dataset = concatenate_datasets([
dataset['test'],
dataset['validation'],
dataset['dev'],
dataset3,
dataset2
])
mmlu_prompt2 = """Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Input:
{}
### Response:
{}"""
EOS_TOKEN = tokenizer.eos_token
def formattoconversations3(examples):
questions = examples["Question"]
a_opts = examples["Option A"]
b_opts = examples["Option B"]
c_opts = examples["Option C"]
d_opts = examples["Option D"]
answers = examples["Correct Answer"]
texts = []
for q, a, b, c, d, ans in zip(questions, a_opts, b_opts, c_opts, d_opts, answers):
correct_text = ''
if ans == 'A':
correct_text = a
elif ans == 'B':
correct_text = b
elif ans == 'C':
correct_text = c
elif ans == 'D':
correct_text = d
text1 = mmlu_prompt2.format(q, correct_text) + EOS_TOKEN
texts.append(text1)
return {"text": texts}
apll = dataset.map(formattoconversations3, batched=True)
apll = apll.remove_columns([
'Title','Question', 'Option A', 'Option B', 'Option C',
'Option D', 'Correct Answer','Text'
])
dataset1 = load_dataset("kz-transformers/kazakh-unified-national-testing-mc")
dataset1 = concatenate_datasets([
dataset1['kazakh_and_literature'],
dataset1['world_history'],
dataset1['english'],
dataset1['history_of_kazakhstan'],
dataset1['geography'],
dataset1['biology'],
dataset1['human_society_rights'],
])
def formattoconversations3(examples):
questions = examples["question"]
a_opts = examples["A"]
b_opts = examples["B"]
c_opts = examples["C"]
d_opts = examples["D"]
e_opts = examples["E"]
f_opts = examples["F"]
g_opts = examples["G"]
h_opts = examples["H"]
answers = examples["correct_answer"]
texts = []
for q, a, b, c, d, e, f, g, h, ans in zip(questions, a_opts, b_opts, c_opts, d_opts,
e_opts, f_opts, g_opts, h_opts, answers):
correct_text = ''
if ans == 'A':
correct_text = a
elif ans == 'B':
correct_text = b
elif ans == 'C':
correct_text = c
elif ans == 'D':
correct_text = d
elif ans == 'E':
correct_text = e
elif ans == 'F':
correct_text = f
elif ans == 'G':
correct_text = g
elif ans == 'H':
correct_text = h
text1 = mmlu_prompt2.format(q, correct_text) + EOS_TOKEN
texts.append(text1)
return {"text": texts}
apll1 = dataset1.map(formattoconversations3, batched=True)
apll1 = apll1.remove_columns([
'subject','question', 'A', 'B', 'C', 'D', 'E',
'F', 'G', 'H', 'correct_answer'
])
dataset2 = concatenate_datasets([apll1, apll])
from trl import SFTTrainer
from transformers import TrainingArguments
from unsloth import is_bfloat16_supported
trainer = SFTTrainer(
model = model,
tokenizer = tokenizer,
train_dataset = dataset2,
dataset_text_field = "text",
max_seq_length = max_seq_length,
dataset_num_proc = 8,
packing = False,
args = TrainingArguments(
per_device_train_batch_size = 4,
gradient_accumulation_steps = 5,
warmup_steps = 5,
num_train_epochs = 5,
learning_rate = 1e-4,
fp16 = not is_bfloat16_supported(),
bf16 = is_bfloat16_supported(),
logging_steps = 100,
optim = "adamw_8bit",
weight_decay = 0.01,
lr_scheduler_type = "linear",
seed = 3407,
output_dir = "outputs",
report_to = "none",
),
)
trainer_stats = trainer.train()
trainer.push_to_hub(
"armanibadboy/llama3.1-kazllm-8b-by-arman-ver2",
tokenizer,
token="сіздің_hf_токен"
)
model.push_to_hub(
"armanibadboy/llama3.1-kazllm-8b-by-arman-ver2",
tokenizer,
token="сіздің_hf_токен"
)
tokenizer.push_to_hub(
"armanibadboy/llama3.1-kazllm-8b-by-arman-ver2",
token="сіздің_hf_токен"
)
%%bash
git clone --depth 1 https://github.com/horde-research/lm-evaluation-harness-kk.git
cd lm-evaluation-harness-kk
pip install -e .
!lm_eval \
--model hf \
--model_args pretrained=armanibadboy/llama3.1-kazllm-8b-by-arman-ver2 \
--batch_size 3 \
--num_fewshot 0 \
--tasks mmlu_translated_kk,kazakh_and_literature_unt_mc,kk_biology_unt_mc,kk_constitution_mc,kk_dastur_mc,kk_english_unt_mc,kk_geography_unt_mc,kk_history_of_kazakhstan_unt_mc,kk_human_society_rights_unt_mc,kk_unified_national_testing_mc,kk_world_history_unt_mc \
--output outputҚорытынды
Осылайша, біз A100 GPU-мен есептеу ресурстарын жалға алуға 5000 теңге (~10 доллар) бюджетте болса да, llama-3.1 қазақ тілді моделін (8B параметрлері) файн-тюнинг жүргізуге және неғұрлым "ауқымды" және ұзақ оқыған модельге салыстырмалы түрде жақын нәтижелерге қол жеткізуге болатынын көрсеттік. Бұл ретте сапаны одан әрі жақсарту есебінен мүмкін болады:
* Оқу датасетін кеңейту (Wikipedia және басқа көздер есебінен).
* Параметрлер санын көбейту (3B және одан жоғары).
* Арнайы серверлерде ұзақ мерзімді оқытуды қолдану (өйткені Google Colab-та сеанс уақытының шектеулері бар, ал фондық тарифтер айтарлықтай қымбатқа түседі).
Осы қадамдардың барлығы қазақ тілді тілдік модельдердің белсенді дамуына және чат — боттар мен іздеуден бастап оқыту мен аударма жүйелеріне дейінгі қосымшалардың кең ауқымына үміт артуға мүмкіндік береді.
Google colab сілтемесі осында
1. Введение
В последние годы наблюдается стремительное развитие языковых моделей, способных понимать и генерировать тексты на различных языках. Тем не менее, для казахского языка до сих пор существует ограниченное число качественных открытых моделей и датасетов, что существенно затрудняет достижение результатов, сопоставимых с моделями, обученными на более распространённых языках (английский, китайский, русский и т.д.).
В данной статье мы рассмотрим опыт файн-тюнинга модели на казахском языке, который стоил всего около 10 долларов США (или 5000 тенге) и был проведён с использованием графического процессора A100. Мы сравним полученные результаты с моделью, обучавшейся на более дорогих вычислительных ресурсах продолжительное время, и покажем, что при грамотном подходе даже бюджетное обучение может дать сопоставимые результаты. Помимо этого, мы кратко упомянем потенциальные пути дальнейшего улучшения качества модели за счёт расширения набора данных и увеличения числа параметров до более крупных масштабов (порядка 3 млрд).
2. Обзор существующих решений
2.1 Модель-«референс»: ISSAI/LLama-3.1-KazLLM-1.0-8B
Одной из известных открытых моделей для казахского языка, доступной на Hugging Face, является issai/LLama-3.1-KazLLM-1.0-8B. Эта модель, по данным авторов, обучалась достаточно долго и на специализированном аппаратном обеспечении. Она демонстрирует высокую точность на нескольких казахскоязычных тестовых наборах (MMLU-подобных и других).
2.2 Новая модель: armanibadboy/llama3.1-kazllm-8b-by-arman-ver2
В качестве основы для нашей модели взят репозиторий unsloth/Meta-Llama-3.1-8B-Instruct, а затем был проведён собственный файн-тюнинг на казахском языке. Общие затраты на обучение составили около 5000 тенге (~10 долларов США), и итоговая модель размещена на Hugging Face. Для обучения применялся A100 GPU, что позволило ускорить процесс и обойти некоторые ограничения, связанные с памятью и скоростью вычислений.
3. Использованные датасеты
3.1 Основные датасеты для файн-тюнинга
В рамках нашего эксперимента мы опирались на уже готовые наборы данных, доступные на Hugging Face:
1. kz-transformers/mmlu-translated-kk – переведённый на казахский язык фрагмент MMLU.
2. kz-transformers/kazakh-dastur-mc – тестовые задания по основам законодательства («Дәстүр»).
3. kz-transformers/kazakh-constitution-mc – тестовые задания по Конституции.
4. kz-transformers/kazakh-unified-national-testing-mc – сборник вопросов по ЕНТ (такие предметы, как история, география, английский, биология и т.д.).
Для упрощения обучения эти датасеты были объединены и «превращены» в инструкционно-ответный формат (prompt + правильный ответ).
3.2 Дополнительные перспективы по расширению данных
Существуют и другие датасеты, которые можно интегрировать в обучение, чтобы увеличить масштаб и тем самым потенциально улучшить качество:
• saillab/alpaca-kazakh-cleaned – казахская версия набора инструкций в стиле Alpaca.
• wikimedia/wikipedia (поднабор 20231101.kk) – недавняя выгрузка казахской Википедии.
При добавлении этих датасетов (особенно Википедии) объём обучающей выборки может возрасти в разы. В результате, если увеличить и масштабы модели (например, довести число параметров до 3 млрд), можно рассчитывать на ещё более качественные результаты. Однако подобное расширение требует уже не просто Google Colab, а более серьёзных вычислительных мощностей (например, выделенных серверов или кластеров), поскольку Colab не всегда позволяет работать в фоновом режиме без отключения; а тарифы с отключённой «автоприостановкой» стоят существенно дороже (~49 долларов в месяц и выше).
. Методы и процесс файн-тюнинга
4.1 Исходная модель и окружение
• Исходная модель: unsloth/Meta-Llama-3.1-8B-Instruct.
• Файн-тюнинг:
• Использовался A100 GPU через сервис Google Colab Pro
• Общие расходы – порядка 5000 тенге (10 долларов США). Куплено 100 токенов что хватает на 14 часов обучения
4.2 Технические аспекты обучения
• Использовался фреймворк Hugging Face Transformers и PEFT для более «лёгкого» обучения (LoRA/QLoRA и т.д.).
• Сборка датасетов в «инструкционный» формат, объединение разных наборов, удаление лишних колонок и так далее.
• Настройка гиперпараметров (batch_size, learning rate, epochs и др.) таким образом, чтобы избежать превышения лимитов по VRAM и времени.
5. Оценка качества (Evaluation)
5.1 Набор задач и метрики
Для оценки мы использовали скрипт lm_eval со следующими наборами заданий (MMLU-подобные и UNT-ориентированные):
• mmlu_translated_kk
• kazakh_and_literature_unt_mc
• kk_biology_unt_mc
• kk_constitution_mc
• kk_dastur_mc
• kk_english_unt_mc
• kk_geography_unt_mc
• kk_history_of_kazakhstan_unt_mc
• kk_human_society_rights_unt_mc
• kk_unified_national_testing_mc
• kk_world_history_unt_mc
Основная метрика – accuracy (acc), отображающая процент правильных ответов (zero-shot режим, --num_fewshot 0).
5.2 Результаты
Модель: armanibadboy/llama3.1-kazllm-8b-by-arman-ver2
| Задача | acc | ± (stderr) |
| kazakh_and_literature_unt_mc | 0,1893 | ±0.0067 |
| kk_biology_unt_mc | 0,2263 | ±0.0115 |
| kk_constitution_mc | 0,3667 | ±0.0312 |
| kk_dastur_mc | 0,3177 | ±0.0202 |
| kk_english_unt_mc | 0,2797 | ±0.0104 |
| kk_geography_unt_mc | 0,2987 | ±0.0145 |
| kk_history_of_kazakhstan_unt_mc | 0,232 | ±0.0086 |
| kk_human_society_rights_unt_mc | 0,4362 | ±0.0408 |
| kk_unified_national_testing_mc | 0,2263 | ±0.0115 |
| kk_world_history_unt_mc | 0,3299 | ±0.0145 |
| mmlu_translated_kk | 0,207 | ±0.0120 |
Сравнение: issai/LLama-3.1-KazLLM-1.0-8B (при тех же настройках)
| Задача | acc | ± (stderr) |
| kazakh_and_literature_unt_mc | 0,2088 | ±0.0070 |
| kk_biology_unt_mc | 0,2733 | ±0.0123 |
| kk_constitution_mc | 0,4417 | ±0.0321 |
| kk_dastur_mc | 0,359 | ±0.0208 |
| kk_english_unt_mc | 0,3254 | ±0.0109 |
| kk_geography_unt_mc | 0,3716 | ±0.0153 |
| kk_history_of_kazakhstan_unt_mc | 0,2943 | ±0.0093 |
| kk_human_society_rights_unt_mc | 0,4899 | ±0.0411 |
| kk_unified_national_testing_mc | 0,2733 | ±0.0123 |
| kk_world_history_unt_mc | 0,3782 | ±0.0149 |
| mmlu_translated_kk | 0,2991 | ±0.0135 |
Как видно, модель armanibadboy/llama3.1-kazllm-8b-by-arman-ver2, обученная относительно быстро и всего за 5000 тенге, демонстрирует результаты, которые в ряде задач не так уж и сильно уступают более «взрослой» модели issai/LLama-3.1-KazLLM-1.0-8B. Разрыв заметен, но его нельзя назвать пропастью — особенно с учётом того, что мы не располагали выделенными серверами и многочасовым временем обучения.
6. Причины расхождений с некоторыми лидербордами
При сравнении с различными публичными лидербордами можно обнаружить заметные расхождения в показателях (как для issai/LLama-3.1-KazLLM-1.0-8B, так и для других моделей). Ниже перечислены основные факторы:
1. Версии датасетов. В лидербордах могут использоваться иные версии тестовых наборов либо особая фильтрация.
2. Разные настройки оценки. Количество few-shot-примеров, temperature, top_p и прочие параметры генерации могут влиять на результат.
3. Обновления модели. Авторы иногда выкладывают новые веса или заново переобученные версии.
4. Выбор лучшего прогона. В некоторых случаях публикуются «лучшие» результаты вместо среднестатистических.
Хочу обратить внимание, что значения для модели issai/LLama-3.1-KazLLM-1.0-8B, полученные мной с помощью lm_eval, сильно отличаются от показателей, представленных на этой странице. По данным лидерборда, модель демонстрирует гораздо более высокие результаты.
Из-за этого может показаться, что моя модель уступает вдвое, хотя при запуске тех же тестов, которые перечислены на указанном ресурсе, разница между моделями оказывается не такой заметной.
Если владелец данного лидерборда читает эти строки, пожалуйста, обновите результаты на странице. Мне, как человеку, который любит соревнования, хотелось бы видеть максимально актуальные данные и опираться на действительно корректные сравнения.**
7. Выводы и дальнейшая работа
1. Экономичный файн-тюнинг. Эксперимент показывает, что даже за ~10 долларов США (5000 тенге), используя всего лишь Google Colab с A100 GPU, можно добиться достаточно хороших результатов для модели казахского языка.
2. Близкие результаты. Разница между нашей моделью и более «тяжёлой» (issai/LLama-3.1-KazLLM-1.0-8B) всё ещё существует, но не столь критична, учитывая кратность затрат и времени обучения.
3. Расширение датасетов и увеличение параметров. Для дальнейшего повышения качества можно подключить дополнительные датасеты — например, saillab/alpaca-kazakh-cleaned или wikimedia/wikipedia (subset 20231101.kk). Включение всех этих источников может повысить объём данных до нескольких гигабайт, что в свою очередь позволит увеличить модель (до ~3B параметров и выше). Однако тут уже потребуются выделенные сервера или облачные сервисы дороже Colab, так как у Google Colab есть ограничения по времени сеанса и объёму памяти, а режим без отключений стоит около 49 долларов в месяц и выше.
4. Обновление лидербордов. С учётом быстрого прогресса в области казахскоязычных LLM-моделей, важно периодически обновлять результаты официальных таблиц лидеров, чтобы отражать реальные показатели новых и обновлённых моделей.
Приложение: Код эксперимента
Ниже приводится код, который мы использовали для обучения и оценки модели (запускался в среде с A100 GPU). Вы можете адаптировать под свои нужды, изменять гиперпараметры и датасеты.
%%capture
!pip install unsloth
# Также установим последнюю версию Unsloth из репозитория
!pip uninstall unsloth -y && pip install --upgrade --no-cache-dir --no-deps git+https://github.com/unslothai/unsloth.git
from unsloth import FastLanguageModel
import torch
max_seq_length = 2048
dtype = None # Автоопределение (можно задать Float16, BFloat16 и т.д.)
load_in_4bit = False # True при необходимости 4bit-квантования
# Список 4-bit моделей (при желании)
fourbit_models = [
"unsloth/Meta-Llama-3.1-8B-bnb-4bit",
"unsloth/Meta-Llama-3.1-8B-Instruct-bnb-4bit",
# ...
]
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/Meta-Llama-3.1-8B-Instruct",
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
)
# Настраиваем LoRA
model = FastLanguageModel.get_peft_model(
model,
r = 32,
target_modules = [
"q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",
],
lora_alpha = 32,
lora_dropout = 0,
bias = "none",
use_gradient_checkpointing = "unsloth",
random_state = 3407,
use_rslora = False,
loftq_config = None,
)
# Загрузка и подготовка датасетов
from datasets import load_dataset, concatenate_datasets
dataset = load_dataset("kz-transformers/mmlu-translated-kk")
dataset3 = load_dataset("kz-transformers/kazakh-dastur-mc", split='test')
dataset2 = load_dataset("kz-transformers/kazakh-constitution-mc", split='test')
dataset = concatenate_datasets([
dataset['test'],
dataset['validation'],
dataset['dev'],
dataset3,
dataset2
])
mmlu_prompt2 = """Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Input:
{}
### Response:
{}"""
EOS_TOKEN = tokenizer.eos_token
def formattoconversations3(examples):
questions = examples["Question"]
a_opts = examples["Option A"]
b_opts = examples["Option B"]
c_opts = examples["Option C"]
d_opts = examples["Option D"]
answers = examples["Correct Answer"]
texts = []
for q, a, b, c, d, ans in zip(questions, a_opts, b_opts, c_opts, d_opts, answers):
correct_text = ''
if ans == 'A':
correct_text = a
elif ans == 'B':
correct_text = b
elif ans == 'C':
correct_text = c
elif ans == 'D':
correct_text = d
text1 = mmlu_prompt2.format(q, correct_text) + EOS_TOKEN
texts.append(text1)
return {"text": texts}
apll = dataset.map(formattoconversations3, batched=True)
apll = apll.remove_columns([
'Title','Question', 'Option A', 'Option B', 'Option C',
'Option D', 'Correct Answer','Text'
])
dataset1 = load_dataset("kz-transformers/kazakh-unified-national-testing-mc")
dataset1 = concatenate_datasets([
dataset1['kazakh_and_literature'],
dataset1['world_history'],
dataset1['english'],
dataset1['history_of_kazakhstan'],
dataset1['geography'],
dataset1['biology'],
dataset1['human_society_rights'],
])
def formattoconversations3(examples):
questions = examples["question"]
a_opts = examples["A"]
b_opts = examples["B"]
c_opts = examples["C"]
d_opts = examples["D"]
e_opts = examples["E"]
f_opts = examples["F"]
g_opts = examples["G"]
h_opts = examples["H"]
answers = examples["correct_answer"]
texts = []
for q, a, b, c, d, e, f, g, h, ans in zip(questions, a_opts, b_opts, c_opts, d_opts,
e_opts, f_opts, g_opts, h_opts, answers):
correct_text = ''
if ans == 'A':
correct_text = a
elif ans == 'B':
correct_text = b
elif ans == 'C':
correct_text = c
elif ans == 'D':
correct_text = d
elif ans == 'E':
correct_text = e
elif ans == 'F':
correct_text = f
elif ans == 'G':
correct_text = g
elif ans == 'H':
correct_text = h
text1 = mmlu_prompt2.format(q, correct_text) + EOS_TOKEN
texts.append(text1)
return {"text": texts}
apll1 = dataset1.map(formattoconversations3, batched=True)
apll1 = apll1.remove_columns([
'subject','question', 'A', 'B', 'C', 'D', 'E',
'F', 'G', 'H', 'correct_answer'
])
dataset2 = concatenate_datasets([apll1, apll])
from trl import SFTTrainer
from transformers import TrainingArguments
from unsloth import is_bfloat16_supported
trainer = SFTTrainer(
model = model,
tokenizer = tokenizer,
train_dataset = dataset2,
dataset_text_field = "text",
max_seq_length = max_seq_length,
dataset_num_proc = 8,
packing = False,
args = TrainingArguments(
per_device_train_batch_size = 4,
gradient_accumulation_steps = 5,
warmup_steps = 5,
num_train_epochs = 5,
learning_rate = 1e-4,
fp16 = not is_bfloat16_supported(),
bf16 = is_bfloat16_supported(),
logging_steps = 100,
optim = "adamw_8bit",
weight_decay = 0.01,
lr_scheduler_type = "linear",
seed = 3407,
output_dir = "outputs",
report_to = "none",
),
)
trainer_stats = trainer.train()
trainer.push_to_hub(
"armanibadboy/llama3.1-kazllm-8b-by-arman-ver2",
tokenizer,
token="ваш_hf_токен"
)
model.push_to_hub(
"armanibadboy/llama3.1-kazllm-8b-by-arman-ver2",
tokenizer,
token="ваш_hf_токен"
)
tokenizer.push_to_hub(
"armanibadboy/llama3.1-kazllm-8b-by-arman-ver2",
token="ваш_hf_токен"
)
%%bash
git clone --depth 1 https://github.com/horde-research/lm-evaluation-harness-kk.git
cd lm-evaluation-harness-kk
pip install -e .
!lm_eval \
--model hf \
--model_args pretrained=armanibadboy/llama3.1-kazllm-8b-by-arman-ver2 \
--batch_size 3 \
--num_fewshot 0 \
--tasks mmlu_translated_kk,kazakh_and_literature_unt_mc,kk_biology_unt_mc,kk_constitution_mc,kk_dastur_mc,kk_english_unt_mc,kk_geography_unt_mc,kk_history_of_kazakhstan_unt_mc,kk_human_society_rights_unt_mc,kk_unified_national_testing_mc,kk_world_history_unt_mc \
--output outputЗаключение
Таким образом, мы показали, что даже при бюджете в 5000 тенге (~10 долларов) на аренду вычислительных ресурсов с A100 GPU можно провести файн-тюнинг казахскоязычной модели Llama-3.1 (8B параметров) и достичь результатов, относительно близких к более «масштабной» и долго обучавшейся модели. При этом дальнейшее улучшение качества возможно за счёт:
• Расширения обучающего датасета (за счёт Wikipedia и других источников).
• Увеличения числа параметров (до 3B и выше).
• Применения более длительного обучения на выделенных серверах (так как Google Colab имеет ограничения по времени сеанса, а тарифы с фоновым режимом стоят существенно дороже).
Все эти шаги позволяют надеяться на активное развитие казахскоязычных языковых моделей и более широкий спектр приложений — от чат-ботов и поиска до систем обучения и перевода.
Ссылка на google colab ТУТ
 Бөлісу
Бөлісу