Бұл жазба автоматты түрде аударылған. Бастапқы тіл: Орысша



Бұл мақалада біз Python-да қарапайым, бірақ толығымен офлайн дауыстық көмекшіні қалай жазу керектігін қарастырамыз. Ол біледі:
- Микрофон арқылы пайдаланушының сөзін тыңдаңыз.
- Интернетке қосылуды қажет етпейтін Жергілікті Whisper моделі-Faster Whisper көмегімен дауысты тану (мәтінге сөйлеу).
- Бұлтта серверсіз жұмыс істейтін ollama — жергілікті іске қосылған LLM (large language model) көмегімен сұрақты талдаңыз және жауапты қалыптастырыңыз.
- Pyttsx3 кітапханасы арқылы жауап мәтінін (Text-To-speech) дауыстаңыз.
Мұндай ассистенттің басты артықшылығы-ол интернетсіз жұмыс істейді және сіздің жеке деректеріңіз (дауыстық дыбыс, транскрипцияланған мәтін, диалог тарихы) сыртқы қызметтерге берілмейді.
Алдымен келесі пакеттердің орнатылғанына көз жеткізіңіз:
- PyAudio-микрофоннан аудио жазу үшін.
- wave-жазылған дыбысты WAV файлына сақтау үшін (Python стандартты кітапханасы).
- Faster Whisper-Whisper моделі арқылы сөйлеуді тануға арналған жергілікті кітапхана.
- Ollama-Интернетке қосылуды қажет етпейтін жергілікті орнатылған LLM.
- pyttsx3-сөйлеу синтезі кітапханасы (TTS), ол да офлайн режимінде жұмыс істейді.
pip install pyaudio faster-whisper ollama pyttsx3Ассистент жұмысының негізгі кезеңдері:
- Инициализация: кітапханаларды импорттау, PyAudio іске қосу және жазу параметрлерін орнату, жергілікті Whisper моделін жүктеу (Faster Whisper),дауыстық қозғалтқышты инициализациялау (pyttsx3),Ollama қол жетімділігін тексеру (оның жергілікті жерде жұмыс істейтініне және желіге кіруді қажет етпейтініне көз жеткізіңіз).
- Кітапханаларды импорттау,
- PyAudio іске қосыңыз және жазу параметрлерін реттеңіз,
- Жергілікті Whisper моделін жүктеу (Faster Whisper),
- Дауыстық қозғалтқыш инициализациясы (pyttsx3),
- Ollama қол жетімділігін тексеру (оның жергілікті жерде жұмыс істейтініне және желіге кіруді қажет етпейтініне көз жеткізіңіз).
- Дауыстық пәрменді жазу: Код PyAudio жазу ағынын ашады және микрофонды "тыңдайды".Пайдаланушы сөйлеуді тоқтатқан кезде дыбыс деңгейі (RMS) бойынша анықтайды.Бірнеше секунд үнсіздіктен кейін ол жазбаны автоматты түрде тоқтатады және оны WAV файлына сақтайды.
- Код pyaudio жазу ағынын ашады және микрофонды "тыңдайды".
- Пайдаланушы сөйлеуді тоқтатқан кезде дыбыс деңгейі (RMS) бойынша анықтайды.
- Бірнеше секунд үнсіздіктен кейін ол жазбаны автоматты түрде тоқтатады және оны WAV файлына сақтайды.
- Сөйлеуді тану (мәтінге сөйлеу):WAV файлы Faster Whisper-ге (жергілікті модель) жіберіледі.Модель шифрланған мәтінді бұлтқа ешқандай деректер жібермей қайтарады.
- WAV файлы Faster Whisper-ге (жергілікті модель) жіберіледі.
- Модель шифрланған мәтінді бұлтқа ешқандай деректер жібермей қайтарады.
- Жауап генерациясы: диалог тарихына транскрипцияланған мәтін (пайдаланушы сұрағы) қосылады.Бүкіл оқиға интернетсіз жергілікті жұмыс істейтін Олламаға жіберіледі.Оллама жүктелген үлкен тіл моделін қолдана отырып жауап қалыптастырады.
- Диалог тарихына транскрипцияланған мәтін (пайдаланушы сұрағы) қосылады.
- Бүкіл оқиға интернетсіз жергілікті жұмыс істейтін Олламаға жіберіледі.
- Оллама жүктелген үлкен тіл моделін қолдана отырып жауап қалыптастырады.
- Жауап дауысы (мәтіннен сөйлеуге дейін):көмекші pyttsx3 арқылы жауап береді.Барлығы офлайн режимінде болады және онлайн қызметтерге тәуелді емес.
- Көмекші pyttsx3 арқылы жауап береді.
- Барлығы офлайн режимінде болады және онлайн қызметтерге тәуелді емес.
Төменде сипатталған функцияларды жүзеге асыратын кодтың мысалы келтірілген.
import pyaudio
import wave
import time
import sys
import struct
import math
from faster_whisper import WhisperModel
import ollama
import pyttsx3
import threading
engine = pyttsx3.init()
model_size = "large-v3"
model = WhisperModel(model_size, device="cpu", compute_type="int8")
CHUNK = 1024 # бір кадрдағы үлгілер саны
RATE = 16000 # іріктеу жылдамдығы
FORMAT = pyaudio.paInt16
CHANNELS = 1
# Дыбыс деңгейі шегі, оның астында пайдаланушы "үнсіз"деп есептейміз
THRESHOLD = 300
# Жазуды тоқтату үшін қанша секунд қатарынан "үндемеу" керек
SILENCE_LIMIT = 2.0
# Мұнда біз диалогтың бүкіл тарихын сақтаймыз
messages = []
def rms(data):
"""
Бір байт блогы үшін шамамен көлемді (RMS) есептеңіз.
деректер: PyAudio-дан оқылған байт жолы
"""
count = len (data) / / 2 # int16 форматындағы санақ Саны
format_str = "<" + "h" * count
shorts = struct.unpack_from(format_str, data)
sum_squares = 0.0
for sample in shorts:
sum_squares += sample * sample
if count == 0:
return 0
return math.sqrt(sum_squares / count)
def record_once(filename="audio.wav"):
"""
Біз сөйлеудің бір бөлігін жазамыз ("үнсіздікке" дейін) және WAV файлына сақтаймыз.
Жазылған файлға жолды қайтарыңыз.
"""
p = pyaudio.PyAudio()
stream = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=CHUNK)
frames = []
басып шығару ("жазуды бастау (сөйлеңіз)...")
silence_counter = 0 # "тыныш" chunk ' s есептегіші
while True:
data = stream.read(CHUNK)
frames.append(data)
# Ағымдағы CHUNK көлемін есептейік
current_rms = rms(data)
if current_rms < THRESHOLD:
# Шекті деңгейден төмен дыбыс => "үнсіздік"
silence_counter += 1
else:
silence_counter = 0
# Егер үнсіз блоктардың жалпы ұзындығы silence_limit секундынан асып кетсе, шығыңыз
if silence_counter * (CHUNK / RATE) > SILENCE_LIMIT:
break
басып шығару ("жазу аяқталды.")
stream.stop_stream()
stream.close()
p.terminate()
# WAV файлына сақтаңыз
wf = wave.open(filename, 'wb')
wf.setnchannels(CHANNELS)
wf.setsampwidth(p.get_sample_size(FORMAT))
wf.setframerate(RATE)
wf.writeframes(b''.join(frames))
wf.close()
return filename
def transcribe(filename):
"""
Файлды faster_whisper көмегімен танимыз.
Біз танылған мәтінді қайтарамыз.
"""
segments, info = model.transcribe(filename, beam_size=8)
print("Detected language '%s' with probability %f" % (info.language, info.language_probability))
texts = ''
for segment in segments:
texts += segment.text
return texts
def main():
while True:
# 1. Сөйлеу үзіндісін жазу
audio_path = record_once("audio.wav")
# 2. Біз танимыз
user_text = transcribe(audio_path)
# Егер кенеттен тану бос жолды қайтарса-өткізіп жіберіңіз
if not user_text.strip():
print ("пайдаланушы ештеңе айтқан жоқ немесе танылған жоқ, біз тыңдай береміз...")
continue
басып шығару ("пайдаланушы айтты:", user_text)
# 3. Пайдаланушының жаңа хабарламасы ретінде тарихқа қосыңыз
messages.append({"role": "user", "content": user_text})
# 4. Біз бүкіл оқиғаны Олламаға жібереміз
# ollama.chat хабарламалар тізімін жіберуге мүмкіндік береді
response = ollama.chat(
'qwen2.5-coder:latest',
messages=messages,
)
# 5. Жауап мәтінін шығарыңыз
assistant_text = response['message']['content']
print ("Assistant жауап берді:", assistant_text)
# 6. Ассистенттің жауабын тарихқа сақтаңыз
messages.append({"role": "assistant", "content": assistant_text})
# 7. Жауап беру
engine.say(assistant_text)
engine.runAndWait()
# Әрі қарай цикл қайталанады, біз қайтадан жазамыз және т. б.
if __name__ == "__main__":
main()
- Faster Whisper-Whisper-дің жергілікті нұсқасы. Сөйлеуді тануға арналған барлық дыбыстық өңдеу сіздің компьютеріңізде.
- Ollama-егер сіз қалаған тіл үлгісін алдын ала жүктеп алсаңыз, бұл құрал толығымен интернет қосылымынсыз жұмыс істей алады. Жауаптың генерациясы жергілікті жерде жүреді.
- pyttsx3-сыртқы API қолданбайтын мәтін-сөйлеу кітапханасы. Барлығы компьютерде синтезделеді.
- PyAudio - микрофоннан дыбысты жергілікті түрде оқиды және оны желіге жібермейді.
Осылайша, ассистент жұмысының ешқандай кезеңі сіздің деректеріңізді Интернетке жібермейді. Сіз Whisper (немесе басқа LLM) модельдері мен нұсқаларын өзіңіз басқарасыз.
- Модельді таңдау: жылдамдық пен тану дәлдігі арасындағы тепе-теңдікті табу үшін әртүрлі faster Whisper (small, medium, large) үлгілерін қолданып көріңіз.
- Шуды болдырмау: егер сізде шулы орта болса, шуды болдырмау және тану сапасын жақсарту үшін кітапхана қосуға болады.
- Балама тілдік модельдер: Ollama тек qwen2.5-coder-ді ғана емес, сонымен қатар басқа модельдерді де қолдайды. Тапсырмаларыңызға сәйкес келетінін таңдаңыз (мысалы, кодты құру, ортақ чат, аударымдар және т.б.).
- GUI: көмекшіні басқару және танылған мәтін мен жауаптарды көру үшін қарапайым GUI қосыңыз (мысалы, PyQt немесе tkinter-де).
Біз микрофонды жазудан және сөйлеуді танудан бастап, жауапты құруға және дауыстауға дейін интернетсіз жұмыс істейтін офлайн дауыстық көмекшіні құрдық. Бұл жеке деректердің қауіпсіздігін қамтамасыз етудің және жүйені өзіңіз үшін икемді түрде орнатудың тамаша тәсілі. Енді сіз ассистенттің функционалдығын кеңейте аласыз, оны әртүрлі командаларды орындауға және күрделі диалогтарды өңдеуге үйрете аласыз — барлығы жергілікті және деректерді толық басқара отырып.
Тәжірибе жасаңыз, жаңа мүмкіндіктер қосыңыз және жергілікті көмекшіңіз жұмыс пен күнделікті өмірде таптырмас құрал болсын!
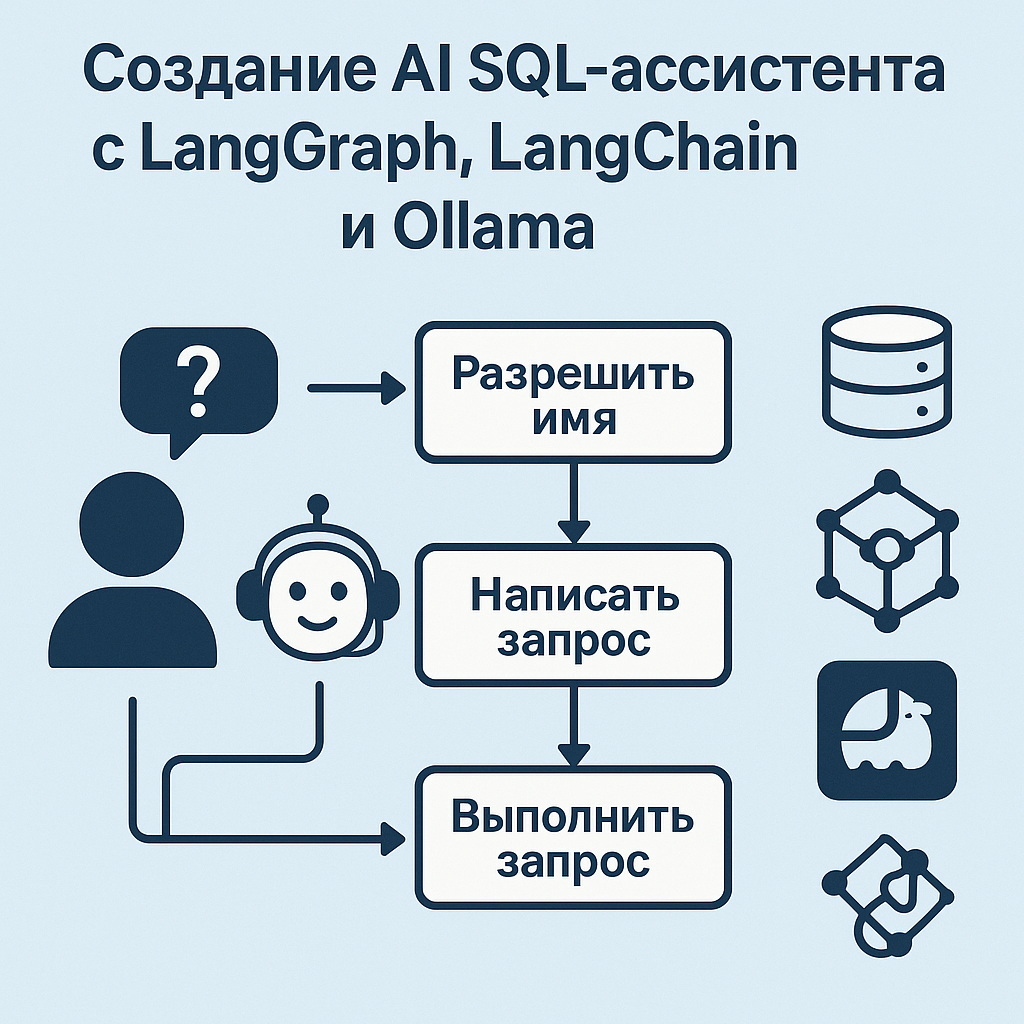
В этой статье мы рассмотрим, как написать простого, но полностью офлайн-голосового ассистента на Python. Он умеет:
- Слушать речь пользователя через микрофон.
- Распознавать голос (speech-to-text), используя Faster Whisper — локальную модель Whisper, не требующую подключения к интернету.
- Анализировать вопрос и формировать ответ с помощью Ollama — локально запущенной LLM (large language model), работающей без сервера в облаке.
- Озвучивать текст ответа (text-to-speech) через библиотеку pyttsx3.
Главное преимущество такого ассистента — он работает без интернета, и ваши личные данные (звук голоса, расшифрованный текст, история диалога) не передаются в какие-либо внешние сервисы.
Сначала убедитесь, что у вас установлены следующие пакеты:
- PyAudio – для записи аудио с микрофона.
- wave – для сохранения записанного звука в WAV-файл (стандартная библиотека Python).
- Faster Whisper – локальная библиотека для распознавания речи с помощью модели Whisper.
- Ollama – локально установленная LLM, не требующая подключения к интернету.
- pyttsx3 – библиотека синтеза речи (TTS), которая тоже работает офлайн.
pip install pyaudio faster-whisper ollama pyttsx3Основные этапы работы ассистента:
- Инициализация:Импорт библиотек,Запуск PyAudio и настройка параметров записи,Загрузка локальной модели Whisper (Faster Whisper),Инициализация движка озвучки (pyttsx3),Проверка доступности Ollama (убедитесь, что она запущена локально и не требует доступа в сеть).
- Импорт библиотек,
- Запуск PyAudio и настройка параметров записи,
- Загрузка локальной модели Whisper (Faster Whisper),
- Инициализация движка озвучки (pyttsx3),
- Проверка доступности Ollama (убедитесь, что она запущена локально и не требует доступа в сеть).
- Запись голосовой команды:Код открывает поток записи PyAudio и «слушает» микрофон.Определяет, когда пользователь перестал говорить, по уровню громкости (RMS).После нескольких секунд тишины автоматически останавливает запись и сохраняет ее в WAV-файл.
- Код открывает поток записи PyAudio и «слушает» микрофон.
- Определяет, когда пользователь перестал говорить, по уровню громкости (RMS).
- После нескольких секунд тишины автоматически останавливает запись и сохраняет ее в WAV-файл.
- Распознавание речи (speech-to-text):WAV-файл передается в Faster Whisper (локальная модель).Модель возвращает расшифрованный текст без отправки каких-либо данных в облако.
- WAV-файл передается в Faster Whisper (локальная модель).
- Модель возвращает расшифрованный текст без отправки каких-либо данных в облако.
- Генерация ответа:Расшифрованный текст (вопрос пользователя) добавляется в историю диалога.Вся история отправляется в Ollama, которая работает локально без интернета.Ollama формирует ответ, используя загруженную большую языковую модель.
- Расшифрованный текст (вопрос пользователя) добавляется в историю диалога.
- Вся история отправляется в Ollama, которая работает локально без интернета.
- Ollama формирует ответ, используя загруженную большую языковую модель.
- Озвучивание ответа (text-to-speech):Ассистент озвучивает ответ через pyttsx3.Все происходит офлайн и не зависит от онлайн-сервисов.
- Ассистент озвучивает ответ через pyttsx3.
- Все происходит офлайн и не зависит от онлайн-сервисов.
Ниже приведен пример кода, в котором реализованы описанные функции.
import pyaudio
import wave
import time
import sys
import struct
import math
from faster_whisper import WhisperModel
import ollama
import pyttsx3
import threading
engine = pyttsx3.init()
model_size = "large-v3"
model = WhisperModel(model_size, device="cpu", compute_type="int8")
CHUNK = 1024 # Количество сэмплов в одном фрейме
RATE = 16000 # Частота дискретизации
FORMAT = pyaudio.paInt16
CHANNELS = 1
# Порог громкости, ниже которого считаем, что пользователь «молчит»
THRESHOLD = 300
# Сколько секунд подряд нужно «молчать», чтобы остановить запись
SILENCE_LIMIT = 2.0
# Здесь храним всю историю диалога
messages = []
def rms(data):
"""
Вычисляем примерную громкость (RMS) для одного блока байт.
data: байтовая строка, считанная из PyAudio
"""
count = len(data) // 2 # Количество отсчетов при формате int16
format_str = "<" + "h" * count
shorts = struct.unpack_from(format_str, data)
sum_squares = 0.0
for sample in shorts:
sum_squares += sample * sample
if count == 0:
return 0
return math.sqrt(sum_squares / count)
def record_once(filename="audio.wav"):
"""
Записываем один фрагмент речи (до 'тишины') и сохраняем в WAV-файл.
Возвращаем путь к записанному файлу.
"""
p = pyaudio.PyAudio()
stream = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=CHUNK)
frames = []
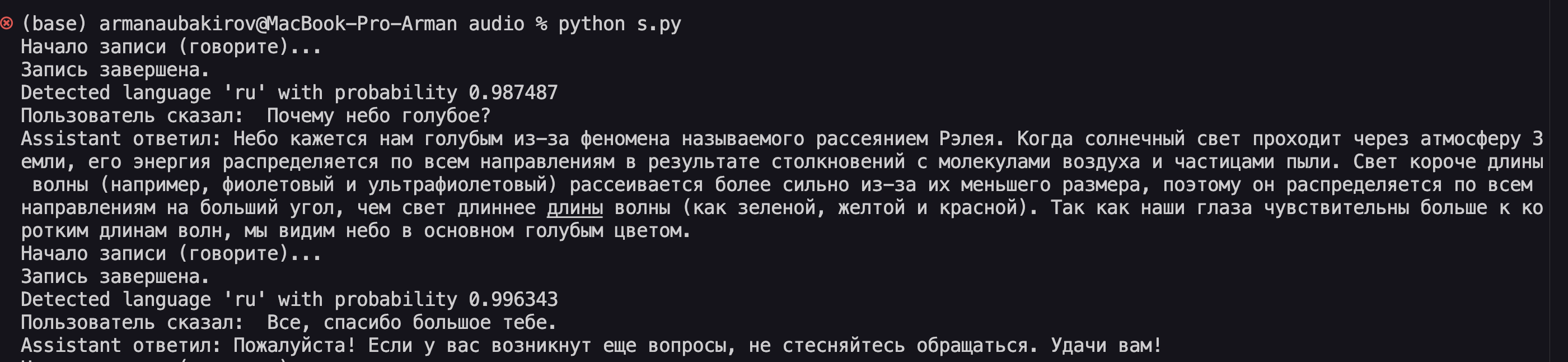
print("Начало записи (говорите)...")
silence_counter = 0 # Счётчик «тихих» CHUNK’ов
while True:
data = stream.read(CHUNK)
frames.append(data)
# Посчитаем громкость текущего CHUNK
current_rms = rms(data)
if current_rms < THRESHOLD:
# Громкость ниже порога => «тишина»
silence_counter += 1
else:
silence_counter = 0
# Если суммарная длина тихих блоков превысила SILENCE_LIMIT секунд, выходим
if silence_counter * (CHUNK / RATE) > SILENCE_LIMIT:
break
print("Запись завершена.")
stream.stop_stream()
stream.close()
p.terminate()
# Сохраняем в WAV-файл
wf = wave.open(filename, 'wb')
wf.setnchannels(CHANNELS)
wf.setsampwidth(p.get_sample_size(FORMAT))
wf.setframerate(RATE)
wf.writeframes(b''.join(frames))
wf.close()
return filename
def transcribe(filename):
"""
Распознаём файл с помощью faster_whisper.
Возвращаем распознанный текст.
"""
segments, info = model.transcribe(filename, beam_size=8)
print("Detected language '%s' with probability %f" % (info.language, info.language_probability))
texts = ''
for segment in segments:
texts += segment.text
return texts
def main():
while True:
# 1. Запись фрагмента речи
audio_path = record_once("audio.wav")
# 2. Распознаём
user_text = transcribe(audio_path)
# Если вдруг распознавание вернуло пустую строку — пропускаем
if not user_text.strip():
print("Пользователь ничего не сказал или не распознано, продолжаем слушать...")
continue
print("Пользователь сказал:", user_text)
# 3. Добавляем в историю как новое сообщение от пользователя
messages.append({"role": "user", "content": user_text})
# 4. Отправляем ВСЮ историю в Ollama
# ollama.chat позволяет передавать список сообщений
response = ollama.chat(
'qwen2.5-coder:latest',
messages=messages,
)
# 5. Извлекаем текст ответа
assistant_text = response['message']['content']
print("Assistant ответил:", assistant_text)
# 6. Сохраняем ответ ассистента в историю
messages.append({"role": "assistant", "content": assistant_text})
# 7. Озвучиваем ответ
engine.say(assistant_text)
engine.runAndWait()
# Далее цикл повторяется, снова записываем и т.д.
if __name__ == "__main__":
main()
- Faster Whisper — локальная версия Whisper. Вся обработка звука для распознавания речи идет внутри вашего компьютера.
- Ollama — этот инструмент может работать полностью без подключения к интернету, если вы заранее скачаете нужную языковую модель. Генерация ответа происходит локально.
- pyttsx3 — библиотека текст-в-речь, которая не использует внешние API. Все синтезируется на вашем компьютере.
- PyAudio — читает звук с микрофона локально и не пересылает его в сеть.
Таким образом, никакой этап работы ассистента не отправляет ваши данные в интернет. Вы сами контролируете, какие модели и версии Whisper (или других LLM) вы используете.
- Выбор модели: Попробуйте разные модели Faster Whisper (small, medium, large), чтобы найти баланс между скоростью и точностью распознавания.
- Шумоподавление: Если у вас шумная среда, можно добавить библиотеку для шумоподавления и улучшить качество распознавания.
- Альтернативные языковые модели: Ollama поддерживает не только qwen2.5-coder, но и другие модели. Выберите ту, которая лучше подходит для ваших задач (например, для генерации кода, общего чата, переводов и т. д.).
- Графический интерфейс: Добавьте простой GUI (например, на PyQt или tkinter), чтобы управлять ассистентом и видеть распознанный текст и ответы.
Мы создали офлайн-голосового ассистента, который полностью работает без интернета — от записи микрофона и распознавания речи до генерации и озвучивания ответа. Это отличный способ обеспечить сохранность личных данных и гибко настраивать систему под себя. Теперь вы можете расширять функциональность ассистента, обучая его выполнять разные команды и обрабатывать сложные диалоги — все это локально и с полным контролем над данными.
Экспериментируйте, добавляйте новые функции, и пусть ваш локальный ассистент станет незаменимым инструментом в работе и повседневной жизни!
 Бөлісу
Бөлісу