The post has been translated automatically. Original language: Russian



1. Introduction
In recent years, there has been a rapid development of language models capable of understanding and generating texts in various languages. Nevertheless, there are still a limited number of high-quality open models and datasets for the Kazakh language, which makes it difficult to achieve results comparable to models trained in more common languages (English, Chinese, Russian, etc.).
In this article, we will look at the experience of fine tuning the model in Kazakh, which cost only about 10 US dollars (or 5,000 tenge) and was carried out using an A100 GPU. We will compare the results obtained with a model that has been trained on more expensive computing resources for a long time, and show that with a competent approach, even budget-based training can produce comparable results. In addition, we will briefly mention potential ways to further improve the quality of the model by expanding the data set and increasing the number of parameters to a larger scale (about 3 billion).
2. Overview of existing solutions
2.1 Reference model: ISSAI/LLama-3.1-KazLLM-1.0-8B
One of the well-known open models for the Kazakh language available on Hugging Face is issai/LLama-3.1-KazLLM-1.0-8B. According to the authors, this model has been trained for a long time and on specialized hardware. It demonstrates high accuracy on several Kazakh-language test kits (MMLU-like and others).
2.2 New model: armanibadboy/LLAMA3.1-KAZLLM-8B-by-arman-ver2
The unsloth/Meta-Llama-3.1-8B-Instruct repository was used as the basis for our model, and then our own fine tuning was conducted in Kazakh. The total cost of training was about 5,000 tenge (~10 US dollars), and the final model is posted on Hugging Face. A100 GPU was used for training, which allowed to speed up the process and circumvent some limitations related to memory and computing speed.
3. Used datasets
3.1 Basic datasets for fine tuning
As part of our experiment, we relied on ready-made datasets available on Hugging Face.:
1. kz-transformers/mmlu-translated-kk is a fragment of the MMLU translated into Kazakh.
2. kz-transformers/Kazakh-dastur-mc – test tasks on the basics of legislation ("Dastur").
3. kz-transformers/Kazakh-constitution-mc – Constitutional test tasks.
4. kz-transformers/Kazakh-unified-national-testing-mc – collection of UNT questions (subjects such as history, geography, English, biology, etc.).
To simplify learning, these datasets were combined and "turned" into an instructional response format (prompt + correct response).
3.2 Additional perspectives on data expansion
There are other datasets that can be integrated into training to increase scale and thus potentially improve quality.:
• saillab/alpaca-kazakh-cleaned is the Kazakh version of the Alpaca–style instruction set.
• wikimedia/wikipedia (subset 20231101.kk) – recent upload of the Kazakh Wikipedia.
With the addition of these datasets (especially Wikipedia), the size of the training sample can increase significantly. As a result, if you increase the scale of the model (for example, bring the number of parameters to 3 billion), you can expect even better results. However, such an extension requires not just Google Colab, but more serious computing power (for example, dedicated servers or clusters), since Colab does not always allow you to work in the background without disconnecting; and tariffs with auto-shutdown are significantly more expensive (~$49 per month and above).
. Methods and process of fine tuning
4.1 Initial model and environment
• Source model: unsloth/Meta-Llama-3.1-8B-Instruct.
• Fine tuning:
• A100 GPU was used via Google Colab Pro service
• Total expenses – about 5,000 tenge (10 US dollars). 100 tokens were purchased, which is enough for 14 hours of training
4.2 Technical aspects of training
• Hugging Face Transformers and PEFT frameworks were used for easier learning (LoRA/QLoRA, etc.).
• Assembling datasets into an "instructional" format, combining different sets, removing unnecessary columns, and so on.
• Configure hyperparameters (batch_size, learning rate, epochs, etc.) in such a way as to avoid exceeding VRAM and time limits.
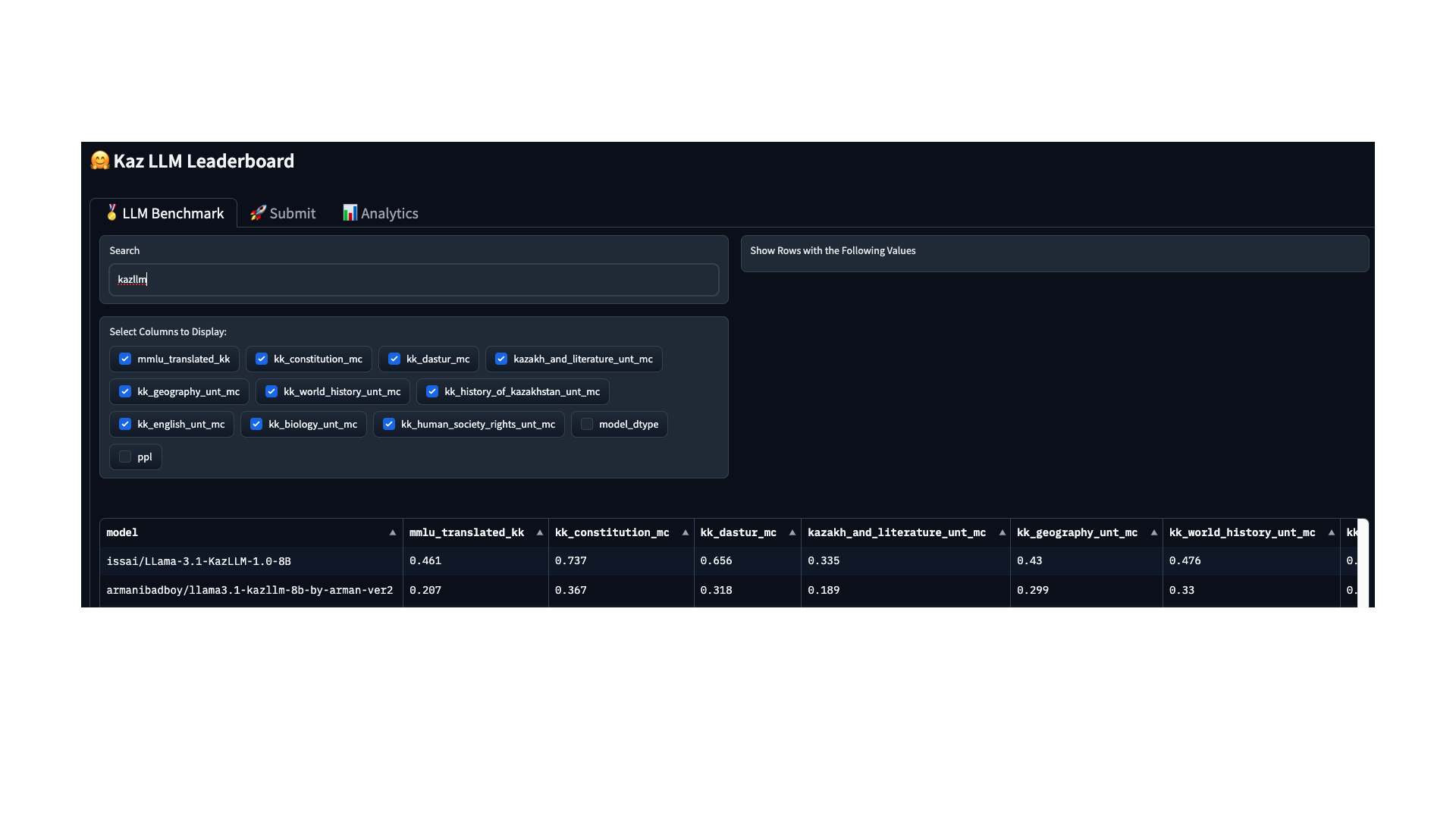
5. Quality Assessment
5.1 Set of tasks and metrics
For evaluation, we used the lm_eval script with the following sets of tasks (MMLU-like and UNT-oriented):
• mmlu_translated_kk
• kazakh_and_literature_unt_mc
• kk_biology_unt_mc
• kk_constitution_mc
• kk_dastur_mc
• kk_english_unt_mc
• kk_geography_unt_mc
• kk_history_of_kazakhstan_unt_mc
• kk_human_society_rights_unt_mc
• kk_unified_national_testing_mc
• kk_world_history_unt_mc
The main metric is accuracy (acc), which displays the percentage of correct answers (zero-shot mode, --num_fewshot 0).
5.2 Results
Model: armanibadboy/llama3.1-kazllm-8B-by-arman-ver2
| Task | acc | ± (stderr) |
| kazakh_and_literature_unt_mc | 0,1893 | ±0.0067 |
| kk_biology_unt_mc | 0,2263 | ±0.0115 |
| kk_constitution_mc | 0,3667 | ±0.0312 |
| kk_dastur_mc | 0,3177 | ±0.0202 |
| kk_english_unt_mc | 0,2797 | ±0.0104 |
| kk_geography_unt_mc | 0,2987 | ±0.0145 |
| kk_history_of_kazakhstan_unt_mc | 0,232 | ±0.0086 |
| kk_human_society_rights_unt_mc | 0,4362 | ±0.0408 |
| kk_unified_national_testing_mc | 0,2263 | ±0.0115 |
| kk_world_history_unt_mc | 0,3299 | ±0.0145 |
| mmlu_translated_kk | 0,207 | ±0.0120 |
Comparison: issai/LLama-3.1-KazLLM-1.0-8B (with the same settings)
| Task | acc | ± (stderr) |
| kazakh_and_literature_unt_mc | 0,2088 | ±0.0070 |
| kk_biology_unt_mc | 0,2733 | ±0.0123 |
| kk_constitution_mc | 0,4417 | ±0.0321 |
| kk_dastur_mc | 0,359 | ±0.0208 |
| kk_english_unt_mc | 0,3254 | ±0.0109 |
| kk_geography_unt_mc | 0,3716 | ±0.0153 |
| kk_history_of_kazakhstan_unt_mc | 0,2943 | ±0.0093 |
| kk_human_society_rights_unt_mc | 0,4899 | ±0.0411 |
| kk_unified_national_testing_mc | 0,2733 | ±0.0123 |
| kk_world_history_unt_mc | 0,3782 | ±0.0149 |
| mmlu_translated_kk | 0,2991 | ±0.0135 |
As can be seen, the armanibadboy/llama3.1-kazllm-8b-by-arman-ver2 model, trained relatively quickly and for only 5,000 tenge, demonstrates results that are not so much inferior to the more "adult" issai/LLama-3.1-KazLLM-1.0-8B model in a number of tasks. The gap is noticeable, but it cannot be called a gap — especially considering that we did not have dedicated servers and many hours of training time.
6. Reasons for discrepancies with some leaderboards
When comparing with various public leaderboards, noticeable differences in indicators can be found (both for issai/LLama-3.1-KazLLM-1.0-8B and for other models). The main factors are listed below:
1. Versions of datasets. Leaderboards may use different versions of test suites or special filtering.
2. Different assessment settings. The number of few-shot examples, temperature, top_p, and other generation parameters can affect the result.
3. Model updates. The authors sometimes post new weights or newly retrained versions.
4. Choosing the best run. In some cases, the "best" results are published instead of the average ones.
I would like to draw your attention to the fact that the values for the issai/LLama-3.1-KazLLM-1.0-8B model, obtained by me using lm_eval, are very different from the indicators presented on this page. According to the leaderboard, the model shows much better results.
Because of this, it may seem that my model is twice as inferior, although when running the same tests listed on the specified resource, the difference between the models is not so noticeable.
If the owner of this leaderboard is reading these lines, please update the results on the page. As a person who loves competitions, I would like to see the most up-to-date data and rely on really correct comparisons.**
7. Conclusions and further work
1. Economical fine tuning. The experiment shows that even for ~10 US dollars (5,000 tenge), using only Google Colab with A100 GPU, you can achieve fairly good results for the Kazakh language model.
2. Close results. The difference between our model and the more "heavy" one (issai/LLama-3.1-KazLLM-1.0-8B) still exists, but it is not so critical, given the multiplicity of costs and training time.
3. Expanding datasets and increasing parameters. To further improve the quality, you can connect additional datasets, such as saillab/alpaca—kazakh-cleaned or wikimedia/wikipedia (subset 20231101.kk). The inclusion of all these sources can increase the amount of data to several gigabytes, which in turn will increase the model (up to ~3B parameters and higher). However, this will require dedicated servers or cloud services that are more expensive than Colab, since Google Colab has limitations on session time and memory, and the shutdown mode costs about $49 per month and above.
4. Updating the leaderboards. Given the rapid progress in the field of Kazakh-language LLM models, it is important to periodically update the results of the official leaderboards to reflect the actual performance of new and updated models.
Application: The experiment code
Below is the code that we used to train and evaluate the model (running in an environment with an A100 GPU). You can adapt it to your needs, change hyperparameters and datasets.
%%capture
!pip install unsloth
# We will also install the latest version of Unsloth from the repository
!pip uninstall unsloth -y && pip install --upgrade --no-cache-dir --no-deps git+https://github.com/unslothai/unsloth.git
from unsloth import FastLanguageModel
import torch
max_seq_length = 2048
dtype = None # Auto-detection (Float16, BFloat16, etc. can be set)
load_in_4bit = False # True if 4bit quantization is required
# List of 4-bit models (if desired)
fourbit_models = [
"unsloth/Meta-Llama-3.1-8B-bnb-4bit",
"unsloth/Meta-Llama-3.1-8B-Instruct-bnb-4bit",
# ...
]
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/Meta-Llama-3.1-8B-Instruct",
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
)
# Configuring LoRA
model = FastLanguageModel.get_peft_model(
model,
r = 32,
target_modules = [
"q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",
],
lora_alpha = 32,
lora_dropout = 0,
bias = "none",
use_gradient_checkpointing = "unsloth",
random_state = 3407,
use_rslora = False,
loftq_config = None,
)
# Uploading and preparing datasets
from datasets import load_dataset, concatenate_datasets
dataset = load_dataset("kz-transformers/mmlu-translated-kk")
dataset3 = load_dataset("kz-transformers/kazakh-dastur-mc", split='test')
dataset2 = load_dataset("kz-transformers/kazakh-constitution-mc", split='test')
dataset = concatenate_datasets([
dataset['test'],
dataset['validation'],
dataset['dev'],
dataset3,
dataset2
])
mmlu_prompt2 = """Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Input:
{}
### Response:
{}"""
EOS_TOKEN = tokenizer.eos_token
def formattoconversations3(examples):
questions = examples["Question"]
a_opts = examples["Option A"]
b_opts = examples["Option B"]
c_opts = examples["Option C"]
d_opts = examples["Option D"]
answers = examples["Correct Answer"]
texts = []
for q, a, b, c, d, ans in zip(questions, a_opts, b_opts, c_opts, d_opts, answers):
correct_text = ''
if ans == 'A':
correct_text = a
elif ans == 'B':
correct_text = b
elif ans == 'C':
correct_text = c
elif ans == 'D':
correct_text = d
text1 = mmlu_prompt2.format(q, correct_text) + EOS_TOKEN
texts.append(text1)
return {"text": texts}
apll = dataset.map(formattoconversations3, batched=True)
apll = apll.remove_columns([
'Title','Question', 'Option A', 'Option B', 'Option C',
'Option D', 'Correct Answer','Text'
])
dataset1 = load_dataset("kz-transformers/kazakh-unified-national-testing-mc")
dataset1 = concatenate_datasets([
dataset1['kazakh_and_literature'],
dataset1['world_history'],
dataset1['english'],
dataset1['history_of_kazakhstan'],
dataset1['geography'],
dataset1['biology'],
dataset1['human_society_rights'],
])
def formattoconversations3(examples):
questions = examples["question"]
a_opts = examples["A"]
b_opts = examples["B"]
c_opts = examples["C"]
d_opts = examples["D"]
e_opts = examples["E"]
f_opts = examples["F"]
g_opts = examples["G"]
h_opts = examples["H"]
answers = examples["correct_answer"]
texts = []
for q, a, b, c, d, e, f, g, h, ans in zip(questions, a_opts, b_opts, c_opts, d_opts,
e_opts, f_opts, g_opts, h_opts, answers):
correct_text = ''
if ans == 'A':
correct_text = a
elif ans == 'B':
correct_text = b
elif ans == 'C':
correct_text = c
elif ans == 'D':
correct_text = d
elif ans == 'E':
correct_text = e
elif ans == 'F':
correct_text = f
elif ans == 'G':
correct_text = g
elif ans == 'H':
correct_text = h
text1 = mmlu_prompt2.format(q, correct_text) + EOS_TOKEN
texts.append(text1)
return {"text": texts}
apll1 = dataset1.map(formattoconversations3, batched=True)
apll1 = apll1.remove_columns([
'subject','question', 'A', 'B', 'C', 'D', 'E',
'F', 'G', 'H', 'correct_answer'
])
dataset2 = concatenate_datasets([apll1, apll])
from trl import SFTTrainer
from transformers import TrainingArguments
from unsloth import is_bfloat16_supported
trainer = SFTTrainer(
model = model,
tokenizer = tokenizer,
train_dataset = dataset2,
dataset_text_field = "text",
max_seq_length = max_seq_length,
dataset_num_proc = 8,
packing = False,
args = TrainingArguments(
per_device_train_batch_size = 4,
gradient_accumulation_steps = 5,
warmup_steps = 5,
num_train_epochs = 5,
learning_rate = 1e-4,
fp16 = not is_bfloat16_supported(),
bf16 = is_bfloat16_supported(),
logging_steps = 100,
optim = "adamw_8bit",
weight_decay = 0.01,
lr_scheduler_type = "linear",
seed = 3407,
output_dir = "outputs",
report_to = "none",
),
)
trainer_stats = trainer.train()
trainer.push_to_hub(
"armanibadboy/llama3.1-kazllm-8b-by-arman-ver2",
tokenizer,
token="your_hf_token"
)
model.push_to_hub(
"armanibadboy/llama3.1-kazllm-8b-by-arman-ver2",
tokenizer,
token="your_hf_token"
)
tokenizer.push_to_hub(
"armanibadboy/llama3.1-kazllm-8b-by-arman-ver2",
token="your_hf_token"
)
%%bash
git clone --depth 1 https://github.com/horde-research/lm-evaluation-harness-kk.git
cd lm-evaluation-harness-kk
pip install -e .
!lm_eval \
--model hf \
--model_args pretrained=armanibadboy/llama3.1-kazllm-8b-by-arman-ver2 \
--batch_size 3 \
--num_fewshot 0 \
--tasks mmlu_translated_kk,kazakh_and_literature_unt_mc,kk_biology_unt_mc,kk_constitution_mc,kk_dastur_mc,kk_english_unt_mc,kk_geography_unt_mc,kk_history_of_kazakhstan_unt_mc,kk_human_society_rights_unt_mc,kk_unified_national_testing_mc,kk_world_history_unt_mc \
--output outputConclusion
Thus, we have shown that even with a budget of 5,000 tenge (~$ 10) for the rental of computing resources with A100 GPU, it is possible to fine-tune the Kazakh-language Llama-3.1 model (8B parameters) and achieve results relatively close to a more "large-scale" and long-studied model. At the same time, further quality improvement is possible due to:
• Extensions of the training dataset (due to Wikipedia and other sources).
• Increasing the number of parameters (up to 3B and above).
• The use of longer training on dedicated servers (since Google Colab has session time limits, and tariffs with background mode are significantly more expensive).
All these steps allow us to hope for the active development of Kazakh—speaking language models and a wider range of applications - from chatbots and search to learning and translation systems.
The link to google colab is HERE
1. Введение
В последние годы наблюдается стремительное развитие языковых моделей, способных понимать и генерировать тексты на различных языках. Тем не менее, для казахского языка до сих пор существует ограниченное число качественных открытых моделей и датасетов, что существенно затрудняет достижение результатов, сопоставимых с моделями, обученными на более распространённых языках (английский, китайский, русский и т.д.).
В данной статье мы рассмотрим опыт файн-тюнинга модели на казахском языке, который стоил всего около 10 долларов США (или 5000 тенге) и был проведён с использованием графического процессора A100. Мы сравним полученные результаты с моделью, обучавшейся на более дорогих вычислительных ресурсах продолжительное время, и покажем, что при грамотном подходе даже бюджетное обучение может дать сопоставимые результаты. Помимо этого, мы кратко упомянем потенциальные пути дальнейшего улучшения качества модели за счёт расширения набора данных и увеличения числа параметров до более крупных масштабов (порядка 3 млрд).
2. Обзор существующих решений
2.1 Модель-«референс»: ISSAI/LLama-3.1-KazLLM-1.0-8B
Одной из известных открытых моделей для казахского языка, доступной на Hugging Face, является issai/LLama-3.1-KazLLM-1.0-8B. Эта модель, по данным авторов, обучалась достаточно долго и на специализированном аппаратном обеспечении. Она демонстрирует высокую точность на нескольких казахскоязычных тестовых наборах (MMLU-подобных и других).
2.2 Новая модель: armanibadboy/llama3.1-kazllm-8b-by-arman-ver2
В качестве основы для нашей модели взят репозиторий unsloth/Meta-Llama-3.1-8B-Instruct, а затем был проведён собственный файн-тюнинг на казахском языке. Общие затраты на обучение составили около 5000 тенге (~10 долларов США), и итоговая модель размещена на Hugging Face. Для обучения применялся A100 GPU, что позволило ускорить процесс и обойти некоторые ограничения, связанные с памятью и скоростью вычислений.
3. Использованные датасеты
3.1 Основные датасеты для файн-тюнинга
В рамках нашего эксперимента мы опирались на уже готовые наборы данных, доступные на Hugging Face:
1. kz-transformers/mmlu-translated-kk – переведённый на казахский язык фрагмент MMLU.
2. kz-transformers/kazakh-dastur-mc – тестовые задания по основам законодательства («Дәстүр»).
3. kz-transformers/kazakh-constitution-mc – тестовые задания по Конституции.
4. kz-transformers/kazakh-unified-national-testing-mc – сборник вопросов по ЕНТ (такие предметы, как история, география, английский, биология и т.д.).
Для упрощения обучения эти датасеты были объединены и «превращены» в инструкционно-ответный формат (prompt + правильный ответ).
3.2 Дополнительные перспективы по расширению данных
Существуют и другие датасеты, которые можно интегрировать в обучение, чтобы увеличить масштаб и тем самым потенциально улучшить качество:
• saillab/alpaca-kazakh-cleaned – казахская версия набора инструкций в стиле Alpaca.
• wikimedia/wikipedia (поднабор 20231101.kk) – недавняя выгрузка казахской Википедии.
При добавлении этих датасетов (особенно Википедии) объём обучающей выборки может возрасти в разы. В результате, если увеличить и масштабы модели (например, довести число параметров до 3 млрд), можно рассчитывать на ещё более качественные результаты. Однако подобное расширение требует уже не просто Google Colab, а более серьёзных вычислительных мощностей (например, выделенных серверов или кластеров), поскольку Colab не всегда позволяет работать в фоновом режиме без отключения; а тарифы с отключённой «автоприостановкой» стоят существенно дороже (~49 долларов в месяц и выше).
. Методы и процесс файн-тюнинга
4.1 Исходная модель и окружение
• Исходная модель: unsloth/Meta-Llama-3.1-8B-Instruct.
• Файн-тюнинг:
• Использовался A100 GPU через сервис Google Colab Pro
• Общие расходы – порядка 5000 тенге (10 долларов США). Куплено 100 токенов что хватает на 14 часов обучения
4.2 Технические аспекты обучения
• Использовался фреймворк Hugging Face Transformers и PEFT для более «лёгкого» обучения (LoRA/QLoRA и т.д.).
• Сборка датасетов в «инструкционный» формат, объединение разных наборов, удаление лишних колонок и так далее.
• Настройка гиперпараметров (batch_size, learning rate, epochs и др.) таким образом, чтобы избежать превышения лимитов по VRAM и времени.
5. Оценка качества (Evaluation)
5.1 Набор задач и метрики
Для оценки мы использовали скрипт lm_eval со следующими наборами заданий (MMLU-подобные и UNT-ориентированные):
• mmlu_translated_kk
• kazakh_and_literature_unt_mc
• kk_biology_unt_mc
• kk_constitution_mc
• kk_dastur_mc
• kk_english_unt_mc
• kk_geography_unt_mc
• kk_history_of_kazakhstan_unt_mc
• kk_human_society_rights_unt_mc
• kk_unified_national_testing_mc
• kk_world_history_unt_mc
Основная метрика – accuracy (acc), отображающая процент правильных ответов (zero-shot режим, --num_fewshot 0).
5.2 Результаты
Модель: armanibadboy/llama3.1-kazllm-8b-by-arman-ver2
| Задача | acc | ± (stderr) |
| kazakh_and_literature_unt_mc | 0,1893 | ±0.0067 |
| kk_biology_unt_mc | 0,2263 | ±0.0115 |
| kk_constitution_mc | 0,3667 | ±0.0312 |
| kk_dastur_mc | 0,3177 | ±0.0202 |
| kk_english_unt_mc | 0,2797 | ±0.0104 |
| kk_geography_unt_mc | 0,2987 | ±0.0145 |
| kk_history_of_kazakhstan_unt_mc | 0,232 | ±0.0086 |
| kk_human_society_rights_unt_mc | 0,4362 | ±0.0408 |
| kk_unified_national_testing_mc | 0,2263 | ±0.0115 |
| kk_world_history_unt_mc | 0,3299 | ±0.0145 |
| mmlu_translated_kk | 0,207 | ±0.0120 |
Сравнение: issai/LLama-3.1-KazLLM-1.0-8B (при тех же настройках)
| Задача | acc | ± (stderr) |
| kazakh_and_literature_unt_mc | 0,2088 | ±0.0070 |
| kk_biology_unt_mc | 0,2733 | ±0.0123 |
| kk_constitution_mc | 0,4417 | ±0.0321 |
| kk_dastur_mc | 0,359 | ±0.0208 |
| kk_english_unt_mc | 0,3254 | ±0.0109 |
| kk_geography_unt_mc | 0,3716 | ±0.0153 |
| kk_history_of_kazakhstan_unt_mc | 0,2943 | ±0.0093 |
| kk_human_society_rights_unt_mc | 0,4899 | ±0.0411 |
| kk_unified_national_testing_mc | 0,2733 | ±0.0123 |
| kk_world_history_unt_mc | 0,3782 | ±0.0149 |
| mmlu_translated_kk | 0,2991 | ±0.0135 |
Как видно, модель armanibadboy/llama3.1-kazllm-8b-by-arman-ver2, обученная относительно быстро и всего за 5000 тенге, демонстрирует результаты, которые в ряде задач не так уж и сильно уступают более «взрослой» модели issai/LLama-3.1-KazLLM-1.0-8B. Разрыв заметен, но его нельзя назвать пропастью — особенно с учётом того, что мы не располагали выделенными серверами и многочасовым временем обучения.
6. Причины расхождений с некоторыми лидербордами
При сравнении с различными публичными лидербордами можно обнаружить заметные расхождения в показателях (как для issai/LLama-3.1-KazLLM-1.0-8B, так и для других моделей). Ниже перечислены основные факторы:
1. Версии датасетов. В лидербордах могут использоваться иные версии тестовых наборов либо особая фильтрация.
2. Разные настройки оценки. Количество few-shot-примеров, temperature, top_p и прочие параметры генерации могут влиять на результат.
3. Обновления модели. Авторы иногда выкладывают новые веса или заново переобученные версии.
4. Выбор лучшего прогона. В некоторых случаях публикуются «лучшие» результаты вместо среднестатистических.
Хочу обратить внимание, что значения для модели issai/LLama-3.1-KazLLM-1.0-8B, полученные мной с помощью lm_eval, сильно отличаются от показателей, представленных на этой странице. По данным лидерборда, модель демонстрирует гораздо более высокие результаты.
Из-за этого может показаться, что моя модель уступает вдвое, хотя при запуске тех же тестов, которые перечислены на указанном ресурсе, разница между моделями оказывается не такой заметной.
Если владелец данного лидерборда читает эти строки, пожалуйста, обновите результаты на странице. Мне, как человеку, который любит соревнования, хотелось бы видеть максимально актуальные данные и опираться на действительно корректные сравнения.**
7. Выводы и дальнейшая работа
1. Экономичный файн-тюнинг. Эксперимент показывает, что даже за ~10 долларов США (5000 тенге), используя всего лишь Google Colab с A100 GPU, можно добиться достаточно хороших результатов для модели казахского языка.
2. Близкие результаты. Разница между нашей моделью и более «тяжёлой» (issai/LLama-3.1-KazLLM-1.0-8B) всё ещё существует, но не столь критична, учитывая кратность затрат и времени обучения.
3. Расширение датасетов и увеличение параметров. Для дальнейшего повышения качества можно подключить дополнительные датасеты — например, saillab/alpaca-kazakh-cleaned или wikimedia/wikipedia (subset 20231101.kk). Включение всех этих источников может повысить объём данных до нескольких гигабайт, что в свою очередь позволит увеличить модель (до ~3B параметров и выше). Однако тут уже потребуются выделенные сервера или облачные сервисы дороже Colab, так как у Google Colab есть ограничения по времени сеанса и объёму памяти, а режим без отключений стоит около 49 долларов в месяц и выше.
4. Обновление лидербордов. С учётом быстрого прогресса в области казахскоязычных LLM-моделей, важно периодически обновлять результаты официальных таблиц лидеров, чтобы отражать реальные показатели новых и обновлённых моделей.
Приложение: Код эксперимента
Ниже приводится код, который мы использовали для обучения и оценки модели (запускался в среде с A100 GPU). Вы можете адаптировать под свои нужды, изменять гиперпараметры и датасеты.
%%capture
!pip install unsloth
# Также установим последнюю версию Unsloth из репозитория
!pip uninstall unsloth -y && pip install --upgrade --no-cache-dir --no-deps git+https://github.com/unslothai/unsloth.git
from unsloth import FastLanguageModel
import torch
max_seq_length = 2048
dtype = None # Автоопределение (можно задать Float16, BFloat16 и т.д.)
load_in_4bit = False # True при необходимости 4bit-квантования
# Список 4-bit моделей (при желании)
fourbit_models = [
"unsloth/Meta-Llama-3.1-8B-bnb-4bit",
"unsloth/Meta-Llama-3.1-8B-Instruct-bnb-4bit",
# ...
]
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/Meta-Llama-3.1-8B-Instruct",
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
)
# Настраиваем LoRA
model = FastLanguageModel.get_peft_model(
model,
r = 32,
target_modules = [
"q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",
],
lora_alpha = 32,
lora_dropout = 0,
bias = "none",
use_gradient_checkpointing = "unsloth",
random_state = 3407,
use_rslora = False,
loftq_config = None,
)
# Загрузка и подготовка датасетов
from datasets import load_dataset, concatenate_datasets
dataset = load_dataset("kz-transformers/mmlu-translated-kk")
dataset3 = load_dataset("kz-transformers/kazakh-dastur-mc", split='test')
dataset2 = load_dataset("kz-transformers/kazakh-constitution-mc", split='test')
dataset = concatenate_datasets([
dataset['test'],
dataset['validation'],
dataset['dev'],
dataset3,
dataset2
])
mmlu_prompt2 = """Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Input:
{}
### Response:
{}"""
EOS_TOKEN = tokenizer.eos_token
def formattoconversations3(examples):
questions = examples["Question"]
a_opts = examples["Option A"]
b_opts = examples["Option B"]
c_opts = examples["Option C"]
d_opts = examples["Option D"]
answers = examples["Correct Answer"]
texts = []
for q, a, b, c, d, ans in zip(questions, a_opts, b_opts, c_opts, d_opts, answers):
correct_text = ''
if ans == 'A':
correct_text = a
elif ans == 'B':
correct_text = b
elif ans == 'C':
correct_text = c
elif ans == 'D':
correct_text = d
text1 = mmlu_prompt2.format(q, correct_text) + EOS_TOKEN
texts.append(text1)
return {"text": texts}
apll = dataset.map(formattoconversations3, batched=True)
apll = apll.remove_columns([
'Title','Question', 'Option A', 'Option B', 'Option C',
'Option D', 'Correct Answer','Text'
])
dataset1 = load_dataset("kz-transformers/kazakh-unified-national-testing-mc")
dataset1 = concatenate_datasets([
dataset1['kazakh_and_literature'],
dataset1['world_history'],
dataset1['english'],
dataset1['history_of_kazakhstan'],
dataset1['geography'],
dataset1['biology'],
dataset1['human_society_rights'],
])
def formattoconversations3(examples):
questions = examples["question"]
a_opts = examples["A"]
b_opts = examples["B"]
c_opts = examples["C"]
d_opts = examples["D"]
e_opts = examples["E"]
f_opts = examples["F"]
g_opts = examples["G"]
h_opts = examples["H"]
answers = examples["correct_answer"]
texts = []
for q, a, b, c, d, e, f, g, h, ans in zip(questions, a_opts, b_opts, c_opts, d_opts,
e_opts, f_opts, g_opts, h_opts, answers):
correct_text = ''
if ans == 'A':
correct_text = a
elif ans == 'B':
correct_text = b
elif ans == 'C':
correct_text = c
elif ans == 'D':
correct_text = d
elif ans == 'E':
correct_text = e
elif ans == 'F':
correct_text = f
elif ans == 'G':
correct_text = g
elif ans == 'H':
correct_text = h
text1 = mmlu_prompt2.format(q, correct_text) + EOS_TOKEN
texts.append(text1)
return {"text": texts}
apll1 = dataset1.map(formattoconversations3, batched=True)
apll1 = apll1.remove_columns([
'subject','question', 'A', 'B', 'C', 'D', 'E',
'F', 'G', 'H', 'correct_answer'
])
dataset2 = concatenate_datasets([apll1, apll])
from trl import SFTTrainer
from transformers import TrainingArguments
from unsloth import is_bfloat16_supported
trainer = SFTTrainer(
model = model,
tokenizer = tokenizer,
train_dataset = dataset2,
dataset_text_field = "text",
max_seq_length = max_seq_length,
dataset_num_proc = 8,
packing = False,
args = TrainingArguments(
per_device_train_batch_size = 4,
gradient_accumulation_steps = 5,
warmup_steps = 5,
num_train_epochs = 5,
learning_rate = 1e-4,
fp16 = not is_bfloat16_supported(),
bf16 = is_bfloat16_supported(),
logging_steps = 100,
optim = "adamw_8bit",
weight_decay = 0.01,
lr_scheduler_type = "linear",
seed = 3407,
output_dir = "outputs",
report_to = "none",
),
)
trainer_stats = trainer.train()
trainer.push_to_hub(
"armanibadboy/llama3.1-kazllm-8b-by-arman-ver2",
tokenizer,
token="ваш_hf_токен"
)
model.push_to_hub(
"armanibadboy/llama3.1-kazllm-8b-by-arman-ver2",
tokenizer,
token="ваш_hf_токен"
)
tokenizer.push_to_hub(
"armanibadboy/llama3.1-kazllm-8b-by-arman-ver2",
token="ваш_hf_токен"
)
%%bash
git clone --depth 1 https://github.com/horde-research/lm-evaluation-harness-kk.git
cd lm-evaluation-harness-kk
pip install -e .
!lm_eval \
--model hf \
--model_args pretrained=armanibadboy/llama3.1-kazllm-8b-by-arman-ver2 \
--batch_size 3 \
--num_fewshot 0 \
--tasks mmlu_translated_kk,kazakh_and_literature_unt_mc,kk_biology_unt_mc,kk_constitution_mc,kk_dastur_mc,kk_english_unt_mc,kk_geography_unt_mc,kk_history_of_kazakhstan_unt_mc,kk_human_society_rights_unt_mc,kk_unified_national_testing_mc,kk_world_history_unt_mc \
--output outputЗаключение
Таким образом, мы показали, что даже при бюджете в 5000 тенге (~10 долларов) на аренду вычислительных ресурсов с A100 GPU можно провести файн-тюнинг казахскоязычной модели Llama-3.1 (8B параметров) и достичь результатов, относительно близких к более «масштабной» и долго обучавшейся модели. При этом дальнейшее улучшение качества возможно за счёт:
• Расширения обучающего датасета (за счёт Wikipedia и других источников).
• Увеличения числа параметров (до 3B и выше).
• Применения более длительного обучения на выделенных серверах (так как Google Colab имеет ограничения по времени сеанса, а тарифы с фоновым режимом стоят существенно дороже).
Все эти шаги позволяют надеяться на активное развитие казахскоязычных языковых моделей и более широкий спектр приложений — от чат-ботов и поиска до систем обучения и перевода.
Ссылка на google colab ТУТ
 Share
Share